Ngày 02/04 vừa qua, hội thảo trực tuyến do Gimasys phối hợp cùng Google Cloud…
Hướng dẫn cách lấy mẫu dữ liệu Product từ Google BigQuery
Tóm tắt từ phần 1 về Cách tự nhận mẫu BigQuerry , Google đang đề xuất một giải pháp cho vấn đề lấy mẫu PROD mới từ BigQuery. Giải pháp này cũng cung cấp các biện pháp an toàn để tránh rò rỉ dữ liệu ngoài ý muốn và đồng thời tự động phục vụ. Người dùng sẽ nhận được mẫu mới mỗi ngày, không còn các lược đồ lỗi thời hay mẫu cũ nữa.
Cách thức hoạt động chi tiết
Bạn có thắc mắc liệu phương pháp này có phù hợp với bạn và liệu giải pháp này có tuân thủ chính sách bảo mật của tổ chức bạn không? Các giả định của Google cho rằng DevOps không quan tâm đến việc tự chuẩn bị các mẫu và tốt hơn là để các nhà khoa học dữ liệu tự phục vụ. Trước hết vì không phải trách nhiệm của DevOps là suy luận về dữ liệu, trong khi đó là nơi các nhà khoa học dữ liệu là chuyên gia về chủ đề này.
DevOps
Trong trường hợp này, Google cho rằng bạn chỉ muốn đánh giá một lần liệu bạn có quyền truy cập dữ liệu vào một bảng cụ thể trong sản xuất hay không. Google cũng cho rằng bạn không muốn trung gian thủ công cho mỗi yêu cầu mẫu. Điều này có nghĩa là bạn có thể mã hóa đánh giá của mình trong một tệp JSON đơn giản mà Google gọi là chính sách.
Chính sách
Trong ví dụ JSON sau, có hai phần, limit và default_sample:
- limit: Xác định lượng dữ liệu tối đa bạn có thể lấy ra từ một bảng. Bạn có thể chỉ định số lượng, phần trăm hoặc cả hai. Trong trường hợp bạn chỉ định cả hai, phần trăm sẽ được chuyển đổi thành số lượng và số lượng tối thiểu giữa phần trăm (chuyển đổi thành số lượng) và số lượng sẽ được sử dụng.
- default_sample: Được sử dụng trong trường hợp yêu cầu không tồn tại hoặc bị “lỗi” như một tệp không phải JSON hoặc tệp rỗng.
Ví dụ:
{
“limit”: {
“count”: 300000,
“percentage”: 40.1
},
“default_sample”: {
“size”: {
“count”: 9,
“percentage”: 6.5
},
“spec”: {
“type”: “random”
}
}
}
Giả định sử dụng với vai trò là nhà khoa học dữ liệu
Google giả định rằng bạn là một nhà khoa học dữ liệu muốn xác định xem bạn có quyền truy cập vào dữ liệu sản xuất hay không. Khi bạn có quyền truy cập, bạn sẽ yêu cầu các mẫu khác nhau bất cứ khi nào bạn cần. Khi bạn thức dậy vào ngày hôm sau, các mẫu của bạn sẽ sẵn sàng cho bạn. Hãy xem các định dạng yêu cầu sau:
Một yêu cầu có cấu trúc giống như mục default_sample trong chính sách, bao gồm:
- size: Chỉ định lượng dữ liệu của bảng mà bạn mong muốn. Bạn có thể chỉ định số lượng, phần trăm hoặc cả hai. Trong trường hợp bạn chỉ định cả hai, giá trị lớn hơn giữa số lượng và phần trăm (chuyển đổi thành số lượng) sẽ được sử dụng làm giá trị thực tế.
- spec: Chỉ định cách lấy mẫu dữ liệu sản xuất bằng cách cung cấp các thông tin sau:
- type: Có thể là sorted (sắp xếp) hoặc random (ngẫu nhiên).
- properties: Nếu là sorted, chỉ định cột nào để sử dụng cho việc sắp xếp và hướng sắp xếp:
- by: Tên cột.
- direction: Hướng sắp xếp (có thể là ASC hoặc DESC).
Ví dụ
{
“__doc__”: “Full sample request”,
“__table_source__”: “bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2015”,
“size”: {
“count”: 3000,
“percentage”: 11.7
},
“spec”: {
“type”: “sorted”,
“properties”: {
“by”: “dropoff_datetime”,
“direction”: “DESC”
}
}
}
Cụ thể hơn về nội dung này, Google sẽ đưa ra một ví dụ. Điều này sẽ giúp bạn hiểu được thế nào là giới hạn và kích thước khi triển khai trên BigQuery.
Giới hạn không phải là kích thước
Có một sự khác biệt nhỏ nhưng quan trọng về cách mà giới hạn khác với kích thước. Trong chính sách, bạn có một giới hạn, sử dụng giá trị nhỏ nhất giữa số lượng và phần trăm. Giới hạn được sử dụng để hạn chế lượng dữ liệu được cung cấp. Kích thước được sử dụng cho các yêu cầu và lấy mẫu mặc định. Nó sử dụng giá trị lớn nhất giữa số lượng và phần trăm, kích thước không được vượt quá giới hạn.
Cách hoạt động của giới hạn và kích thước trong BigQuery
Bảng trong kịch bản này có 50.000 hàng.
| Field | Where | count | percentage |
| limit | Policy | 30,000 | 10 |
| size | Request | 10,000 | 40 |
Sau đó nó được chuyển thành:
| Field | Where | count | percentage | % in row count | Final value | Semantic |
| limit | Policy | 30,000 | 10 | 5,000 | 5,000 | min(30000, 5000) |
| size | Request | 10,000 | 40 | 20,000 | 20,000 | max(10000, 20000) |
Trong trường hợp này, kích thước mẫu có giới hạn là 5.000 hàng, tương đương 10% của 50.000 hàng.
Chu kỳ lấy mẫu
Trong Hình bên dưới đây, bạn có luồng của việc lấy mẫu dữ liệu mà bỏ qua cơ sở hạ tầng:
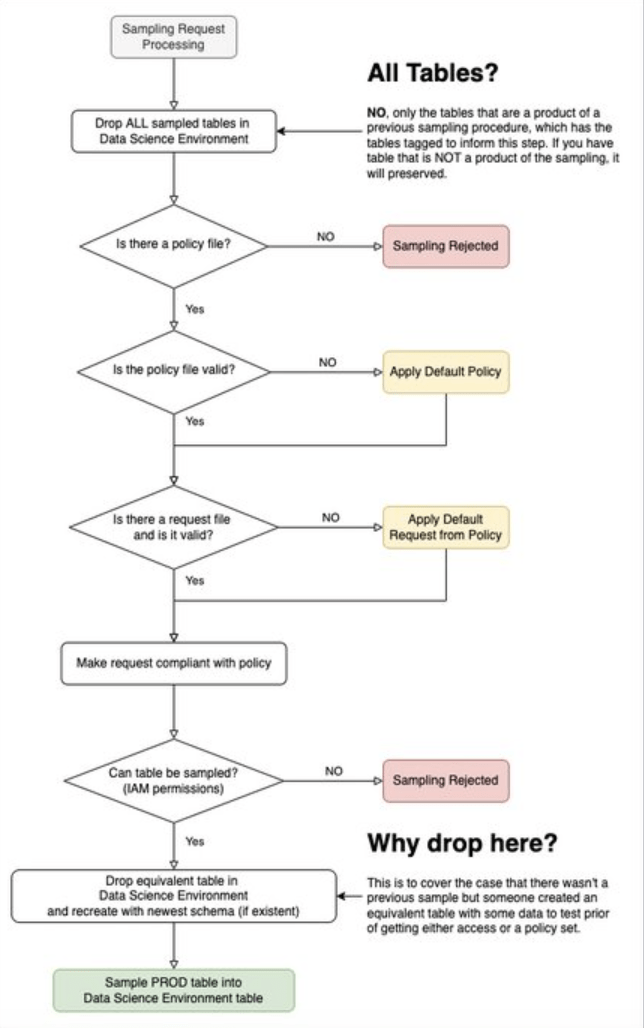
Hình trên có thể trông có vẻ phức tạp và người dùng cần đảm bảo rằng:
- Không xảy ra lạm phát mẫu, tức là mẫu của bạn không nên tăng lên sau mỗi chu kỳ lấy mẫu. Nghĩa là các chính sách phải được tuân thủ.
- Bạn phải chịu lỗi các yêu cầu không hợp lệ.
- Giữ các lược đồ đồng bộ với sản xuất.
Chi tiết, trình lấy mẫu có luồng như sau:
- Cloud Scheduler đặt một thông báo START vào chủ đề COMMAND của PubSub. Nó báo cho hàm sampler bắt đầu lấy mẫu.
- Hàm sampler sẽ làm những việc sau:
- Xóa tất cả các mẫu trước đó trong môi trường Khoa học Dữ liệu.
- Liệt kê tất cả các chính sách có sẵn trong bucket chính sách.
- Đối với mỗi bảng mà nó tìm thấy, gửi lệnh SAMPLE_START với chính sách tương ứng.
- Đối với mỗi lệnh SAMPLE_START, kiểm tra xem có tệp yêu cầu tương ứng không. Chúng ở trong bucket yêu cầu.
- Yêu cầu được kiểm tra theo chính sách.
- Một yêu cầu lấy mẫu tuân thủ được gửi đến nguồn BigQuery. Nó được chèn vào bảng tương ứng trong Môi trường Khoa học Dữ liệu.
- Mỗi lỗi mà hàm sampler tìm thấy, nó sẽ báo cáo vào chủ đề ERROR của PubSub.
- Hàm xử lý lỗi được kích hoạt bởi bất kỳ thông báo nào trong chủ đề này. Nó gửi email thông báo về lỗi.
- Giả sử rằng hàm sampler không được thực thi trong vòng 24 giờ. Sau đó, nó kích hoạt một cảnh báo được gửi đến chủ đề ERROR của PubSub.
- Nếu có lỗi “nghiêm trọng” trong cả việc lấy mẫu hoặc hàm xử lý lỗi, nó gửi một cảnh báo qua email.
Giới hạn
Google sẽ đề cập chi tiết từng điểm trong các phần sau. Để tham khảo, dưới đây là danh sách ngắn về những điều mà Google không hỗ trợ:
- Các JOINs bất kỳ loại nào
- Các câu lệnh WHERE
- Tự động làm mờ (dữ liệu được tự động ẩn danh trước khi chèn mẫu)
- Loại trừ cột
- Loại trừ hàng
- Phân phối lấy mẫu đồng nhất chính xác
- Phân phối lấy mẫu dữ liệu không đồng nhất (như Gaussian, Power, và Pareto)
Google sẽ đưa ra các “giải thích” về các “KHÔNG” – phần lớn thuộc một trong các loại sau:
- Quá phức tạp và tốn thời gian để triển khai.
- Bạn có thể sử dụng các views.
- Sẽ quá đắt đối với bạn để có nó. Chúng tôi sẽ giải quyết từng mục trong danh sách trong các phần tiếp theo.
JOINs và WHEREs
Vấn đề với JOINs và WHEREs là quá phức tạp để triển khai nhằm thực thi một chính sách lấy mẫu. Dưới đây là một ví dụ đơn giản:
- Bảng TYPE_OF_AIRCRAFT, là một ID đơn giản cho một máy bay cụ thể, ví dụ, Airbus A320 neo có ID ABC123. 100% dữ liệu được lấy mẫu, tức là bạn có thể sao chép bảng.
- Bảng FLIGHT_LEG, là một chuyến bay cụ thể vào một ngày cụ thể, ví dụ, London Heathrow đến Berlin lúc 14:50 Chủ Nhật. Mười phần trăm được lấy mẫu.
- Bảng PASSENGER_FLIGHT_LEG cung cấp thông tin hành khách ngồi ở đâu trong một FLIGHT_LEG cụ thể. Chỉ cho phép 10 hàng.
Bạn bây giờ có thể tạo một truy vấn kết hợp tất cả các bảng này lại với nhau. Bạn có thể hỏi tất cả hành khách bay trên một loại máy bay cụ thể vào một ngày cụ thể. Trong trường hợp này, để tuân thủ các chính sách, chúng tôi phải thực hiện những việc sau:
- Thực thi truy vấn.
- Xác minh lượng dữ liệu từ mỗi bảng cụ thể được kéo qua truy vấn.
- Bắt đầu giới hạn dựa trên “khoản cho phép”.
Quá trình này sẽ:
- Khó triển khai mà không có một SQL AST.
- Có thể rất đắt đối với bạn. Vì vậy, chúng tôi sẽ thực thi và sau đó “cắt tỉa” (bạn phải trả tiền cho truy vấn đầy đủ).
- Có nhiều trường hợp cạnh có thể vi phạm các chính sách.
- Nguy cơ rò rỉ dữ liệu.
Làm mờ dữ liệu
Google hiểu rằng nhiều người dùng cần làm mờ dữ liệu vì tính chất bảo mật. Việc này được giải quyết bởi Cloud DLP và cũng có nhiều giải pháp có khả năng hơn trên thị trường mà bạn có thể sử dụng. Xem bài viết trên blog: Quản lý dữ liệu của bạn: sử dụng Cloud DLP để nhận diện và làm mờ thông tin nhạy cảm.
Thao tác loại trừ cột & hàng
Google đồng ý rằng loại trừ cột và hàng là đơn giản, và thậm chí còn dễ dàng hơn, an toàn hơn khi sử dụng các views hoặc Cloud DLP. Lý do Google không thực hiện điều này ở đây là vì đây là một trường hợp sử dụng khó để tạo ra một đặc tả chung có thể hoạt động cho tất cả các trường hợp sử dụng. Ngoài ra, còn có những cách tiếp cận tốt hơn nhiều như Cloud DLP. Tất cả phụ thuộc vào lý do tại sao bạn muốn loại bỏ cột hoặc hàng.
Có xảy ra việc đồng nhất khi thực hiện không?
Ngoại trừ các views, Google dựa vào các câu lệnh TABLESAMPLE với lý do là chi phí. Một mẫu thực sự ngẫu nhiên có nghĩa là sử dụng chiến lược ORDER BY RAND(), điều này yêu cầu quét toàn bộ bảng. Với các câu lệnh TABLESAMPLE, bạn chỉ phải trả một chút nhiều hơn số lượng dữ liệu bạn muốn.
Lưu ý về các câu lệnh TABLESAMPLE
Kỹ thuật này cho phép Google lấy mẫu một bảng mà không cần đọc toàn bộ. Nhưng có một LƯU Ý lớn khi sử dụng TABLESAMPLE. Nó không thực sự ngẫu nhiên cũng không đồng nhất. Mẫu của bạn sẽ có sự thiên lệch trong các khối bảng của bạn. Dưới đây là cách nó hoạt động, theo tài liệu:
Ví dụ sau đây đọc khoảng 20% các khối dữ liệu từ kho lưu trữ và sau đó ngẫu nhiên chọn 10% các hàng trong các khối đó:
SELECT * FROM dataset.my_table TABLESAMPLE SYSTEM (20 PERCENT)
WHERE rand() < 0.1
Một ví dụ luôn dễ hiểu hơn. Hãy tạo một ví dụ với nhiều sự lệch để cho thấy TABLESAMPLE làm gì. Hãy tưởng tượng bảng của bạn có một cột số nguyên duy nhất. Bây giờ hình dung rằng các khối của bạn có các đặc điểm sau:
| Block ID | Average | Distribution | Description |
| 1 | 10 | Single value | All values are 10 |
| 2 | 9 | Single value | All values are 9 |
| 3 | 5 | Uniform from 0 to 10 | |
| 4 | 4 | Uniform from -1 to 9 | |
| 5 | 0 | Uniform from -5 to 5 |
Ở thời điểm này, chúng ta quan tâm đến việc xem xét điều gì xảy ra với giá trị trung bình của mẫu của bạn khi sử dụng TABLESAMPLE. Để đơn giản, giả sử rằng:
- Mỗi khối có 1.000 bản ghi. Điều này đặt giá trị trung bình thực tế của tất cả các giá trị trong bảng vào khoảng 5,6.
- Bạn đã chọn mẫu 40%.
- TABLESAMPLE sẽ lấy mẫu 40% các khối và bạn sẽ nhận được hai khối. Hãy xem xét giá trị trung bình của bạn. Giả sử rằng các khối có Block ID 1 và 2 đã được chọn. Điều này có nghĩa là giá trị trung bình của mẫu của bạn bây giờ là 9,5. Ngay cả khi bạn sử dụng phương pháp giảm mẫu được đề xuất trong tài liệu, bạn vẫn sẽ có một mẫu bị lệch. Đơn giản là nếu các khối của bạn có sự thiên lệch, mẫu của bạn cũng sẽ có sự thiên lệch.
Một lần nữa, việc loại bỏ sự thiên lệch tiềm năng có nghĩa là tăng chi phí lấy mẫu lên đến mức quét toàn bộ bảng.
Trường hợp người dùng cần nhiều hơn các bảng phân phối khác
Lý do chính là các phân phối khác không được hỗ trợ bởi công cụ SQL. Không có giải pháp thay thế cho tính năng thiếu này. Cách duy nhất để có nó là triển khai nó. Đây là nơi mọi thứ trở nên phức tạp. Cảnh báo trước, nếu thống kê của bạn không tốt, điều này sẽ rất khó khăn.
Tất cả các câu lệnh dưới đây đều dựa trên thuộc tính kỳ lạ của hàm phân phối tích lũy (CDF): Đối với một phân phối cho trước, CDF của nó được phân phối liên tục.
Để nó hoạt động, bạn sẽ cần làm như sau:
- Lấy tất cả dữ liệu trên cột mục tiêu (đang là mục tiêu của phân phối).
- Tính toán CDF của cột.
- Lấy mẫu ngẫu nhiên/đồng đều của CDF.
- Chuyển đổi cái ở trên thành một số hàng/ID.
- Đưa các hàng vào mẫu.
Quá trình này có thể được thực hiện, nhưng có một số hệ lụy, chẳng hạn như:
- Bạn sẽ cần quét toàn bộ bảng.
- Bạn sẽ phải có một instance “mạnh mẽ” để giữ tất cả dữ liệu (nghĩ đến hàng tỷ hàng), và bạn sẽ phải tính toán CDF.
Điều này có nghĩa là bạn sẽ phải trả tiền cho các thứ sau:
- Truy vấn vốn đã đắt đỏ (quét toàn bộ bảng).
- Thời gian trên instance đắt đỏ để tính toán mẫu.
Views: giải pháp thay thế
Google hỗ trợ lấy mẫu từ các views. Điều này có nghĩa là bạn luôn có thể đóng gói điều này và để trình lấy mẫu thực hiện công việc của nó. Nhưng các views không hỗ trợ câu lệnh TABLESAMPLE của BigQuery. Điều này có nghĩa là các mẫu ngẫu nhiên cần quét toàn bộ bảng bằng chiến lược ORDER BY RAND(). Quét toàn bộ bảng không xảy ra trên các mẫu không ngẫu nhiên.
Liệu việc này có gian lận hay không?
Chính xác là thao tác này Google thừa nhận có “gian lận” với giải pháp thay thế sử dụng views đẩy trách nhiệm lên SecOps và DataOps, những người sẽ cần định nghĩa các views tuân thủ và các chính sách lấy mẫu. Ngoài ra, nó có thể tốn kém, vì truy vấn view giống như thực thi truy vấn cơ bản và lấy mẫu nó. Hãy cẩn thận đặc biệt với các mẫu ngẫu nhiên từ views do tính chất quét toàn bộ bảng của nó trên views.
Thiết kế giải pháp
Google đã lựa chọn một giải pháp rất đơn giản với các thành phần sau đây:
- BigQuery: The source and destination of data.
- Cloud Scheduler: Our crontab to trigger the sampling on a daily or regular basis.
- Cloud Pub/Sub: Coordinates the triggering, errors, and sampling steps.
- Cloud Storage: Stores the policies and requests (two different buckets).
- Cloud Functions: Our workhorse for logic.
- Secret Manager: Keeps sensitive information.
- Cloud Monitoring: Monitors the health of the system.
Nguồn: Gimasys
Bài viết liên quan