
Hiện nay, khi làn sóng Generative AI đã bước qua giai đoạn thử nghiệm ban…
Datastream là gì? Thông tin cần biết về Datastream
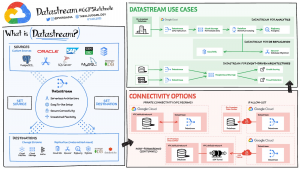
Datastream là gì?
Với khối lượng dữ liệu không ngừng tăng lên, nhiều công ty gặp khó khăn trong việc sử dụng dữ liệu một cách hiệu quả và có được những hiểu biết sâu sắc từ nó. Thông thường các tổ chức này phải chịu gánh nặng với các kiến trúc dữ liệu cồng kềnh và khó bảo trì.
Một cách mà các công ty đang giải quyết thách thức này là thay đổi streaming: sự di chuyển của dữ liệu thay đổi khi chúng xảy ra từ nguồn (thường là cơ sở dữ liệu) đến điểm đến. Được hỗ trợ bởi change data capture – CDC (thay đổi thu thập dữ liệu), phát trực tuyến thay đổi đã trở thành một khối xây dựng kiến trúc dữ liệu quan trọng. Gần đây, chúng tôi đã công bố Datastream, một dịch vụ sao chép và thay đổi thu thập dữ liệu không cần máy chủ. Các khả năng chính của Datastream bao gồm:
- Sao chép và đồng bộ hóa dữ liệu trong tổ chức của bạn với độ trễ tối thiểu. Bạn có thể đồng bộ hóa dữ liệu trên các cơ sở dữ liệu và ứng dụng không đồng nhất một cách đáng tin cậy, với độ trễ thấp và tác động tối thiểu đến hiệu suất nguồn của bạn. Khai thác sức mạnh của các luồng dữ liệu để phân tích, sao chép cơ sở dữ liệu, di chuyển đám mây và event-driven architectures (kiến trúc hướng sự kiện) trên các môi trường kết hợp.
- Tăng hoặc giảm quy mô với kiến trúc không máy chủ một cách liền mạch. Thiết lập và chạy nhanh chóng với dịch vụ không máy chủ và dễ sử dụng, có quy mô liền mạch khi khối lượng dữ liệu của bạn thay đổi. Tập trung vào việc thu thập thông tin chi tiết cập nhật từ dữ liệu của bạn và phản hồi các vấn đề có mức độ ưu tiên cao, thay vì quản lý cơ sở hạ tầng, điều chỉnh hiệu suất hoặc cung cấp tài nguyên.
- Tích hợp với bộ tích hợp dữ liệu Google Cloud Platform. Kết nối dữ liệu trong tổ chức của bạn với các sản phẩm tích hợp dữ liệu Đám mây của Google. Datastream tận dụng các mẫu Dataflow để tải dữ liệu vào BigQuery, Cloud Spanner và Cloud SQL; nó cũng hỗ trợ các đầu nối CDC Replicator của Cloud Data Fusion để tổng hợp dữ liệu dễ dàng hơn bao giờ hết.
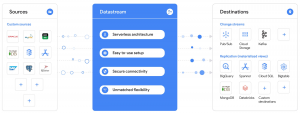
Các trường hợp sử dụng
Datastream nắm bắt các luồng thay đổi từ Oracle, MySQL và các nguồn khác cho các điểm đến như Cloud Storage, Pub / Sub, BigQuery, Spanner, v.v. Một số trường hợp sử dụng của Datastream:
- Đối với phân tích, hãy sử dụng Datastream với mẫu pre-built Dataflow để tạo các bảng sao chép cập nhật trong BigQuery theo cách được quản lý đầy đủ.
- Để sao chép cơ sở dữ liệu, hãy sử dụng Datastream với các mẫu Dataflow được tạo sẵn để liên tục sao chép và đồng bộ hóa dữ liệu cơ sở dữ liệu vào Cloud SQL cho PostgreSQL hoặc Spanner để hỗ trợ di chuyển cơ sở dữ liệu downtime thấp hoặc cấu hình đám mây lai.
- Để xây dựng kiến trúc theo hướng sự kiện, hãy sử dụng Datastream để nhập các thay đổi từ nhiều nguồn vào các kho lưu trữ đối tượng như Google Cloud Storage hoặc trong tương lai, các dịch vụ nhắn tin như Pub / Sub hoặc Kafka
- Hợp lý hoá data pipeline thời gian thực liên tục truyền dữ liệu từ kho dữ liệu quan hệ cũ (như Oracle và MySQL) bằng cách sử dụng Datastream vào MongoDB.
Bạn thiết lập Datastream như thế nào?
- Tạo một cấu hình kết nối nguồn.
- Tạo một cấu hình kết nối đích.
- Tạo một luồng bằng cách sử dụng cấu hình kết nối nguồn và đích, đồng thời xác định các đối tượng để lấy từ nguồn.
- Xác thực và bắt đầu luồng.
Sau khi bắt đầu, một luồng liên tục truyền dữ liệu từ nguồn đến đích. Bạn có thể tạm dừng và sau đó tiếp tục phát trực tiếp.
Tùy chọn kết nối
Để sử dụng Datastream để tạo luồng từ cơ sở dữ liệu nguồn đến đích, bạn phải thiết lập kết nối với cơ sở dữ liệu nguồn. Datastream hỗ trợ danh sách cho phép IP, SSH tunnel chuyển tiếp và các phương thức kết nối mạng ngang hàng VPC.
Cấu hình kết nối riêng tư cho phép Datastream giao tiếp với nguồn dữ liệu qua mạng riêng (nội bộ trong Google Cloud hoặc với các nguồn bên ngoài được kết nối qua VPN hoặc Interconnect). Giao tiếp này xảy ra thông qua kết nối ngang hàng Đám mây riêng ảo (VPC).
Nguồn: Gimasys
Bài viết liên quan


