
Vẻ đẹp của những đóa hoa từ lâu đã là nguồn cảm hứng bất tận…
Cách Google Cloud xây dựng pipeline truyền dữ liệu trực tuyến
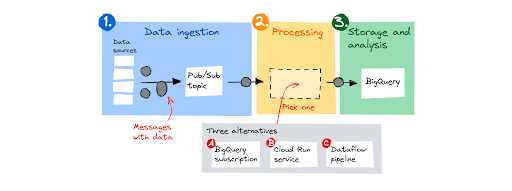
Nhiều khách hàng xây dựng các pipeline truyền dữ liệu trực tuyến để nhập, xử lý và sau đó lưu trữ dữ liệu để phân tích sau này. Google sẽ tập trung vào một thiết kế pipeline phổ biến được hiển thị bên dưới. Nó bao gồm ba bước:
- Nguồn dữ liệu gửi thông báo có dữ liệu đến Pub/Sub topic.
- Pub/Sub đệm các tin nhắn và chuyển tiếp chúng đến một thành phần xử lý.
- Sau khi xử lý, thành phần xử lý lưu trữ dữ liệu trong BigQuery.
Đối với thành phần xử lý, Google sẽ xem xét 3 lựa chọn thay thế, từ cơ bản đến nâng cao: đăng ký BigQuery, dịch vụ Cloud Run và Dataflow pipeline.
Trường hợp sử dụng
Trước khi Google tìm hiểu sâu hơn về chi tiết triển khai, hãy xem xét một vài trường hợp sử dụng về truyền dẫn dữ liệu pipeline:
- Xử lý nhấp chuột quảng cáo. Nhận các nhấp chuột quảng cáo, chạy phỏng đoán dự đoán gian lận trên cơ sở từng nhấp chuột và loại bỏ hoặc lưu trữ để phân tích thêm.
- Chuẩn hóa các định dạng dữ liệu. Nhận dữ liệu từ các nguồn khác nhau, chuẩn hóa chúng thành một mô hình dữ liệu duy nhất và lưu trữ để phân tích hoặc xử lý thêm sau này.
- Chụp từ xa. Lưu trữ các tương tác của người dùng và hiển thị số liệu thống kê theo thời gian thực, chẳng hạn như người dùng đang hoạt động hoặc thời lượng phiên trung bình được nhóm theo loại thiết bị.
- Giữ nhật ký ghi lại dữ liệu thay đổi. Ghi nhật ký tất cả các cập nhật cơ sở dữ liệu từ cơ sở dữ liệu vào BigQuery thông qua Pub/Sub.
Nhập dữ liệu với Pub/Sub
Hãy cùng bắt đầu lại từ đầu. Bạn có một hoặc nhiều nguồn dữ liệu xuất bản thông báo cho Pub/Sub topic. Pub/Sub là dịch vụ nhắn tin được quản lý hoàn toàn. Bạn xuất bản tin nhắn và Pub/Sub đảm nhận việc gửi tin nhắn đến một hoặc nhiều người đăng ký. Cách thuận tiện nhất để xuất bản tin nhắn lên Pub/Sub là sử dụng thư viện khách hàng.
Để xác thực với Pub/Sub, bạn cần cung cấp thông tin xác thực. Nếu nhà sản xuất dữ liệu của bạn chạy trên Google Cloud, các thư viện ứng dụng khách sẽ đảm nhận việc này cho bạn và sử dụng nhận dạng dịch vụ tích hợp. Nếu khối lượng công việc của bạn không chạy trên Google Cloud, bạn nên sử dụng liên kết nhận dạng, hoặc như một phương án cuối cùng,tải xuống khóa tài khoản dịch vụ (nhưng hãy đảm bảo có chiến lược xoay vòng các thông tin xác thực tồn tại lâu dài này).
Các lựa chọn thay thế để xử lý
Điều quan trọng là phải nhận ra rằng một số quy trình rất đơn giản và một số quy trình phức tạp. Các pipeline đơn giản không thực hiện bất kỳ xử lý (hoặc nhẹ) nào trước khi duy trì dữ liệu. pipeline nâng cao tổng hợp các nhóm dữ liệu để giảm yêu cầu lưu trữ dữ liệu và có thể có nhiều bước xử lý.
Google sẽ giới thiệu cách xử lý bằng một trong ba tùy chọn sau:
- Đăng ký BigQuery, một giải pháp truyền qua không cần mã giúp lưu trữ các tin nhắn không thay đổi trong tập dữ liệu BigQuery.
- Dịch vụ Cloud Run, để xử lý nhẹ các thư riêng lẻ mà không cần tổng hợp.
- Một pipeline Dataflow, để xử lý nâng cao (sẽ nói thêm về điều đó sau).
Phương pháp 1: Lưu trữ dữ liệu không thay đổi bằng cách sử dụng đăng ký BigQuery
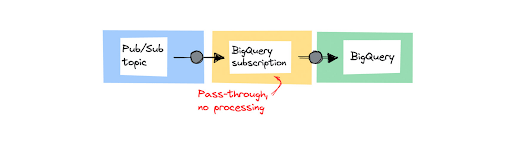
Cách tiếp cận đầu tiên là cách đơn giản nhất. Bạn có thể truyền trực tiếp tin nhắn từ Pub/Sub topic vào bộ dữ liệu BigQuery bằng cách sử dụng đăng ký BigQuery. Sử dụng nó khi bạn đang nhập tin nhắn và không cần thực hiện bất kỳ quá trình xử lý nào trước khi lưu trữ dữ liệu.
Khi thiết lập đăng ký mới cho một chủ đề, bạn chọn Viết thư cho BigQuery tùy chọn, như được hiển thị ở đây:
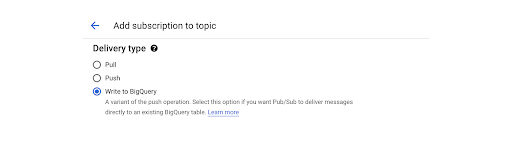
Các chi tiết về cách thức đăng ký này được thực hiện hoàn toàn trừu tượng với người dùng. Điều đó có nghĩa là không có cách nào để thực thi bất kỳ mã nào trên dữ liệu đến. Về bản chất, nó là một giải pháp không có mã. Điều đó có nghĩa là bạn không thể áp dụng lọc trên dữ liệu trước khi lưu trữ.
Bạn cũng có thể sử dụng mẫu này nếu muốn lưu trữ trước và thực hiện xử lý sau trong BigQuery. Điều này thường được gọi là ELT (trích xuất, tải, biến đổi).
Mẹo: Một điều cần lưu ý là không có gì đảm bảo rằng thư được ghi vào BigQuery chính xác một lần, vì vậy hãy đảm bảo loại bỏ trùng lặp dữ liệu khi bạn truy vấn dữ liệu đó sau này.
Phương pháp 2: Xử lý thư riêng lẻ bằng Cloud Run
Sử dụng Cloud Run nếu bạn cần thực hiện một số xử lý nhẹ trên từng thư trước khi lưu trữ chúng. Một ví dụ điển hình về chuyển đổi nhẹ là chuẩn hóa định dạng dữ liệu – trong đó mọi nguồn dữ liệu sử dụng định dạng và trường riêng, nhưng bạn muốn lưu trữ dữ liệu ở một định dạng dữ liệu.
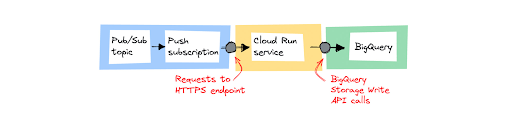
Cloud Run cho phép bạn chạy mã của mình dưới dạng dịch vụ web trực tiếp trên cơ sở hạ tầng của Google. Bạn có thể định cấu hình Pub/Sub thành gửi mọi tin nhắn dưới dạng yêu cầu HTTP bằng đăng ký đẩy đến điểm cuối HTTPS của dịch vụ Cloud Run. Khi có yêu cầu, mã của bạn sẽ xử lý và gọi API ghi bộ lưu trữ BigQuery để chèn dữ liệu vào bảng BigQuery. Bạn có thể sử dụng bất kỳ ngôn ngữ lập trình và khuôn khổ nào bạn muốn trên Cloud Run.
Kể từ tháng 2 năm 2022, đăng ký đẩy (push) là cách được khuyến nghị để tích hợp Pub/Sub với Cloud Run. Đăng ký đẩy sẽ tự động thử lại các yêu cầu nếu chúng không thành công và bạn có thể đặt chủ đề thư chết (dead – letter) để nhận thư thất bại trong tất cả các lần gửi. tham khảo xử lý lỗi tin nhắn để tìm hiểu thêm.
Có thể có những lúc không có dữ liệu nào được gửi đến quy trình của bạn. Trong trường hợp này, Cloud Run sẽ tự động thay đổi số lượng phiên bản thành 0. Ngược lại, nó mở rộng quy mô lên tới 1.000 phiên bản vùng chứa để xử lý tải tối đa. Nếu lo lắng về chi phí, bạn có thể đặt số lượng phiên bản tối đa.
Việc phát triển lược đồ dữ liệu với Cloud Run sẽ dễ dàng hơn. Bạn có thể sử dụng các công cụ đã được thiết lập để xác định và quản lý việc di chuyển lược đồ dữ liệu như Liquibase. Đọc thêm về sử dụng Liquibase với BigQuery.
Để tăng cường bảo mật, hãy đặt chính sách xâm nhập trên các vi dịch vụ Cloud Run của bạn thành nội bộ để chỉ có thể truy cập chúng từ Pub/Sub (và các dịch vụ nội bộ khác), tạo tài khoản dịch vụ cho đăng ký và chỉ cấp cho tài khoản dịch vụ đó quyền truy cập vào dịch vụ Cloud Run. Đọc thêm về thiết lập đăng ký đẩy một cách an toàn.
Cân nhắc sử dụng Cloud Run làm thành phần xử lý trong quy trình của bạn trong những trường hợp sau:
- Bạn có thể xử lý các tin nhắn riêng lẻ mà không yêu cầu nhóm và tổng hợp các tin nhắn.
- Bạn thích sử dụng mô hình lập trình chung hơn là sử dụng SDK chuyên biệt.
- Bạn đã sử dụng Cloud Run để phục vụ các ứng dụng web và thích sự đơn giản và nhất quán trong kiến trúc giải pháp của mình.
Mẹo: Các API ghi lưu trữ hiệu quả hơn cái cũ phương pháp chèn tất cả bởi vì nó sử dụng tính năng phát trực tuyến gRPC thay vì REST qua HTTP.
Phương pháp 3: Xử lý nâng cao và tổng hợp thông báo bằng Dataflow
Cloud Dataflow, một dịch vụ được quản lý hoàn toàn để thực thi Tia Apache pipeline trên Google Cloud, từ lâu đã là nền tảng để xây dựng pipeline phát trực tuyến trên Google Cloud. Đó là một lựa chọn tốt cho các pipeline tổng hợp các nhóm dữ liệu để giảm dữ liệu và những pipeline có nhiều bước xử lý.
Trong một luồng dữ liệu, việc nhóm được thực hiện bằng cách sử dụng cửa sổ. Chức năng cửa sổ nhóm các bộ sưu tập không giới hạn theo dấu thời gian. Có nhiều chiến lược tạo cửa sổ có sẵn, bao gồm cửa sổ cố định, trượt và phiên. Dataflow có hỗ trợ tích hợp để xử lý dữ liệu muộn. Dữ liệu muộn xuất hiện khi một cửa sổ đã đóng và bạn có thể muốn loại bỏ dữ liệu đó hoặc kích hoạt tính toán lại. Tham khảo đến tài liệu về truyền dữ liệu để tìm hiểu thêm.
Cloud Dataflow cũng có thể được tận dụng cho khối lượng công việc AI/ML và phù hợp với người dùng muốn tiền xử lý, đào tạo và đưa ra dự đoán trên mô hình máy học bằng Tensorflow. Đây là một danh sách các hướng dẫn tuyệt vời tích hợp Dataflow vào quy trình học máy từ đầu đến cuối.
Khi xử lý một quy trình phức tạp trong sản xuất – hoặc thậm chí là một quy trình đơn giản – bạn muốn có khả năng quan sát trạng thái và hiệu suất của quy trình của mình. Cloud Dataflow có giao diện người dùng giúp khắc phục sự cố dễ dàng hơn trong quy trình nhiều bước. Thông qua việc tích hợp với Giám sát đám mây, Dataflow cung cấp các chỉ số, nhật ký và cảnh báo phù hợp. Nếu bạn muốn tìm hiểu thêm, hãy tham khảo tuyệt vời này tổng quan về tất cả các tính năng có thể quan sát được trong Dataflow.
Cloud Dataflow hướng đến xử lý dữ liệu quy mô lớn. Spotify đặc biệt sử dụng nó để tính toán danh sách phát Wrapped được cá nhân hóa hàng năm. Đọc này bài đăng blog sâu sắc về quy trình Wrapped năm 2020 trên blog kỹ thuật Spotify.
Dataflow có thể tự động chia tỷ lệ các cụm của nó theo cả chiều dọc và chiều ngang. Người dùng thậm chí có thể sử dụng các phiên bản hỗ trợ GPU trong cụm của họ và Cloud Dataflow sẽ đảm nhận việc đưa nhân viên mới vào cụm để đáp ứng nhu cầu, đồng thời hủy chúng sau đó khi không còn cần thiết.
Nếu bạn quyết định rằng Dataflow phù hợp với khối lượng công việc của mình, hãy xem mẫu được cung cấp giải quyết các tình huống phổ biến. Những điều này sẽ giúp bạn bắt đầu nhanh hơn. Bạn có thể triển khai các mẫu dưới dạng các quy trình đóng gói sẵn. Để điều chỉnh các mẫu theo nhu cầu của bạn, hãy khám phá mã nguồn trên GitHub.
Mẹo: Giới hạn số lượng công nhân tối đa trong cụm để giảm chi phí và thiết lập cảnh báo thanh toán.
Phương pháp nào sẽ phù hợp với bạn?
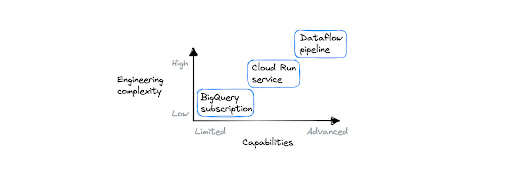
Ba công cụ có khả năng và mức độ phức tạp khác nhau. Dataflow là tùy chọn mạnh mẽ nhất và phức tạp nhất, yêu cầu người dùng sử dụng SDK chuyên dụng (Apache Beam) để xây dựng pipeline của họ. Mặt khác, đăng ký BigQuery không cho phép bất kỳ logic xử lý nào và có thể được định cấu hình bằng bảng điều khiển web. Chọn công cụ phù hợp nhất với nhu cầu của bạn sẽ giúp bạn có được kết quả tốt hơn nhanh hơn.
Đối với các quy trình quy mô lớn (quy mô Spotify) hoặc khi bạn cần giảm dữ liệu bằng cách sử dụng cửa sổ hoặc có một quy trình nhiều bước phức tạp, hãy chọn Dataflow. Trong tất cả các trường hợp khác, bắt đầu với Cloud Run là tốt nhất, trừ khi bạn đang tìm giải pháp không dùng mã để kết nối Pub/Sub với BigQuery. Trong trường hợp đó, hãy chọn đăng ký BigQuery.
Chi phí là một yếu tố khác để xem xét. Luồng dữ liệu trên đám mây áp dụng quy mô tự động, nhưng sẽ không thay đổi quy mô thành 0 trường hợp khi không có dữ liệu đến. Đối với một số nhóm, đây là lý do để chọn Cloud Run thay vì Dataflow.
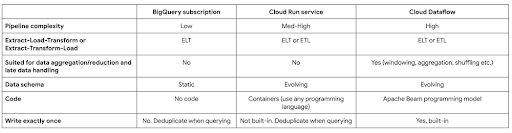
Bảng so sánh này tóm tắt những khác biệt chính.
Cloud đã và đang là xu hướng tất yếu trong hệ thống phát triển , tối ưu công nghệ của các doanh nghiệp. Gimasys – Premier Partner của Google tại Việt Nam là đơn vị cung cấp, tư vấn các cấu trúc, thiết kế giải pháp Cloud tối ưu cho bạn. Để biết được hỗ trợ về mặt chuyên môn kỹ thuật, bạn có thể liên hệ Gimasys – Premier Partner của Google tại Việt Nam theo thông tin:
- Hotline: 0974 417 099 (HCM) | 0987 682 505 (HN)
- Email: gcp@gimasys.com
Nguồn: Gimasys
Bài viết liên quan


