
Nhờ công nghệ lõi "Agentic AI" (AI tự chủ), Trí tuệ nhân tạo đang tiến…
Building streaming data pipelines on Google Cloud
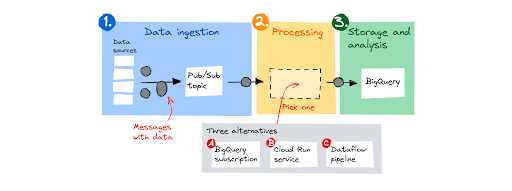
Many customers build streaming data pipelines to ingest, process and then store data for later analysis. Google will focus on a common pipeline design shown below. It consists of three steps:
- Data sources send messages with data to a Pub/Sub topic.
- Pub/Sub buffers the messages and forwards them to a processing component.
- After processing, the processing component stores the data in BigQuery.
For the processing component, Google will consider 3 alternatives, from basic to advanced: registration BigQuery, dịch vụ Cloud Run và Dataflow pipeline.
Example use cases
Before Googlee dive deeper into the implementation details, let’s look at a few example use cases of streaming data pipelines:
- Processing ad clicks. Receiving ad clicks, running fraud prediction heuristics on a click-by-click basis, and discarding or storing them for further analysis.
- Canonicalizing data formats. Receiving data from different sources, canonicalizing them into a single data model, and storing them for later analysis or further processing.
- Capturing telemetry. Storing user interactions and displaying real-time statistics, such as active users, or the average session length grouped by device type.
- Keeping a change data capture log. Logging all database updates from a database to BigQuery through Pub/Sub.
Ingesting data with Pub/Sub
Let’s start at the beginning. You have one or multiple data sources that publish messages to a Pub/Sub topic. Pub/Sub is a fully-managed messaging service. You publish messages, and Pub/Sub takes care of delivering the messages to one or many subscribers. The most convenient way to publish messages to Pub/Sub is to use the client library..
To authenticate with Pub/Sub you need to provide credentials. If your data producer runs on Google Cloud, the client libraries take care of this for you and use the built-in service identity. If your workload is not running on Google Cloud, you should use identity federation, or as a last resort,download a service account key (but make sure to have a strategy to rotate these long-lived credentials).
Three alternatives for processing
It’s important to realize that some pipelines are straightforward, and some are complex. Straightforward pipelines don’t do any (or lightweight) processing before persisting the data. Advanced pipelines aggregate groups of data to reduce data storage requirements and can have multiple processing steps.
Google will cover how to do processing using either one of the following 3 options:
- A BigQuery subscription, a no-code pass-through solution that stores messages unchanged in a BigQuery dataset.
- A Cloud Run service, for lightweight processing of individual messages without aggregation.
- A Dataflow pipeline, for advanced processing (more on that later).
Approach 1: Storing data unchanged using a BigQuery subscription
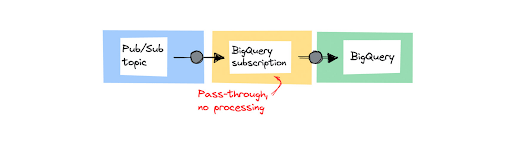
The first approach is the most straightforward one. You can stream messages from a Pub/Sub topic directly into a BigQuery dataset using a Sign up for BigQuery. Use it when you’re ingesting messages and don’t need to perform any processing before storing the data.
When setting up a new subscription to a topic, you select the Write to BigQuery option, as shown here:
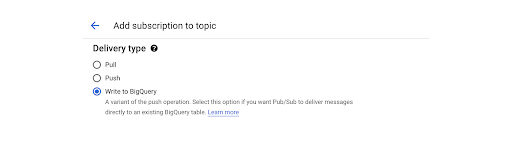
The details of how this subscription is implemented are completely abstracted away from users. That means there is no way to execute any code on the incoming data. In essence, it is a no-code solution. That means you can’t apply filtering on data before storing.
You can also use this pattern if you want to first store, and perform processing later in BigQuery. This is commonly referred to as ELT (extract, load, transform).
Tip: One thing to keep in mind is that there are no guarantees that messages are written to BigQuery exactly once, so make sure to deduplicate the data when you’re querying it later.
Approach 2: Processing messages individually using Cloud Run
Use Cloud Run if you do need to perform some lightweight processing on the individual messages before storing them. A good example of a lightweight transformation is canonicalizing data formats - where every data source uses its own format and fields, but you want to store the data in one data format.
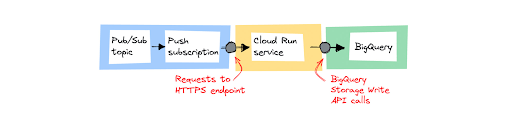
Cloud Run lets you run your code as a web service directly on top of Google’s infrastructure. You can configure Pub/Sub to send every message as an HTTP request using a push subscription to the Cloud Run service’s HTTPS endpoint. When a request comes in, your code does its processing and calls the BigQuery Storage Write API to insert data into a BigQuery table. You can use any programming language and framework you want on Cloud Run.
As of February 2022, push subscriptions are the recommended way to integrate Pub/Sub with Cloud Run. A push subscription automatically retries requests if they fail and you can set a dead-letter topic to receive messages that failed all delivery attempts. Refer to handling message failures to learn more.
There might be moments when no data is submitted to your pipeline. In this case, Cloud Run automatically scales the number of instances to zero. Conversely, it scales all the way up to 1,000 container instances to handle peak load. If you’re concerned about costs, you can set a maximum number of instances.
It’s easier to evolve the data schema with Cloud Run. You can use established tools to define and manage data schema migrations like Liquibase. Read more on using Liquibase with BigQuery.
For added security, set the ingress policy on your Cloud Run microservices to be internal so that they can only be reached from Pub/Sub (and other internal services), create a service account for the subscription, and only give that service account access to the Cloud Run service. Read more about setting up push subscriptions in a secure way..
Consider using Cloud Run as the processing component in your pipeline in these cases:
- You can process messages individually, without requiring grouping and aggregating messages.
- You prefer using a general programming model over using a specialized SDK.
- You’re already using Cloud Run to serve web applications and prefer simplicity and consistency in your solution architecture.
Tip: The API ghi archive is more efficient than the older insertAll method because it uses gRPC streaming rather than REST over HTTP.
Approach 3: Advanced processing and aggregation of messages using Dataflow
Cloud Dataflow, a fully managed service for executing Apache Beam pipelines on Google Cloud, has long been the bedrock of building streaming pipelines on Google Cloud. It is a good choice for pipelines that aggregate groups of data to reduce data and those that have multiple processing steps.
n a data stream, grouping is done using windowing. Windowing functions group unbounded collections by the timestamps. There are multiple windowing strategies available, including fixed, sliding, and session windows. Dataflow has built-in support to handle late data. Late data comes in when a window has already closed, and you might want to discard that data or trigger a recalculation. Refer to the documentation on data streaming to learn more.
Cloud Dataflow can also be leveraged for AI/ML workloads and is suited for users that want to preprocess, train, and make predictions on a machine learning model using Tensorflow. Here’s a list of great tutorials that integrate Dataflow into end-to-end machine learning workflows..
When dealing with a complex pipeline in production - or even a simple one - you want to have visibility into the state and performance of your pipeline. Cloud Dataflow has a UI that makes it easier to troubleshoot issues in multi-step pipelines. Through its integration with Cloud Monitoring, Dataflow provides tailored metrics, logs, and alerting. If you want to learn more, refer to this excellent overview of all the observability features in Dataflow..
Cloud Dataflow is geared toward massive scale data processing. Spotify notably uses it to compute its yearly personalized Wrapped playlists. Read this insightful blogpost about the 2020 Wrapped pipeline on the Spotify engineering blog.
Dataflow can autoscale its clusters both vertically and horizontally. Users can even go as far as using GPU powered instances in their clusters and Cloud Dataflow will take care of bringing new workers into the cluster to meet demand, and also destroy them afterwards when they are no longer needed.
If you decide that Dataflow is the right match for your workload, look at the provided templates that solve common scenarios. These will help you get started faster. You can deploy the templates as pre-packaged pipelines. To adapt the templates to your needs, explore the source code on GitHub..
Tip: Cap the maximum number of workers in the cluster to reduce cost and set up billing alerts.
Which approach should you choose?
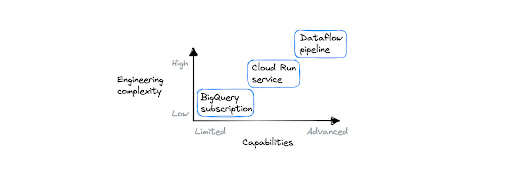
The 3 tools have different capabilities and levels of complexity. Dataflow is the most powerful option and the most complex, requiring users to use a specialized SDK (Apache Beam) to build their pipelines. On the other end, a BigQuery subscription doesn’t allow any processing logic and can be configured using the web console. Choosing the tool that best suits your needs will help you get better results faster.
For massive (Spotify scale) pipelines, or when you need to reduce data using windowing, or have a complex multi-step pipeline, choose Dataflow. In all other cases, starting with Cloud Run is best, unless you’re looking for a no-code solution to connect Pub/Sub to BigQuery. In that case, choose the BigQuery subscription.
Cost is another factor to consider. Cloud Dataflow does apply automatic scaling, but won’t scale to zero instances when there is no incoming data. For some teams, this is a reason to choose Cloud Run over Dataflow.
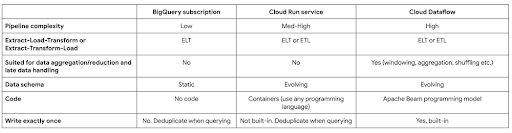
This comparison table summarizes the key differences.
Cloud has been and is an inevitable trend in the technology development and optimization system of enterprises. Gimasys - Premier Partner of Google in Vietnam is the unit providing, consulting the structure, designing the optimal Cloud solution for you. For technical support, you can contact Gimasys - Premier Partner of Google in Vietnam at the following information:
- Hotline: 0974 417 099 (HCM) | 0987 682 505 (HN)
- Email: gcp@gimasys.com
Source: Gimasys
Related Posts


