Ngày 02/04 vừa qua, hội thảo trực tuyến do Gimasys phối hợp cùng Google Cloud…
Google tích hợp Gemini AI vào BigQuery
BigQuery cho phép bạn phân tích dữ liệu của mình bằng cách sử dụng một loạt các mô hình ngôn ngữ lớn (LLMs) được lưu trữ trong Vertex AI bao gồm Gemini 1.0 Pro, Gemini 1.0 Pro Vision và text-bison. Các mô hình này hoạt động tốt cho nhiều nhiệm vụ như tóm tắt văn bản, phân tích tâm trạng, vv. chỉ bằng cách sử dụng kỹ thuật prompt. Tuy nhiên, trong một số tình huống, việc tinh chỉnh bổ sung thông qua việc tinh chỉnh mô hình là cần thiết, như khi hành vi mong đợi của mô hình khó mô tả một cách ngắn gọn trong một prompt, hoặc khi prompt không tạo ra kết quả mong đợi một cách đồng nhất đủ.
Việc tinh chỉnh bổ sung cũng giúp mô hình học các phong cách phản ứng cụ thể (ví dụ: ngắn gọn hoặc dài dòng), các hành vi mới (ví dụ: trả lời dưới dạng một nhân vật cụ thể), hoặc cập nhật mình với thông tin mới.
Hôm nay, Google thông báo về việc hỗ trợ tinh chỉnh tùy chỉnh cho LLM trong BigQuery thông qua việc tinh chỉnh giám sát. Tinh chỉnh giám sát thông qua BigQuery sử dụng một tập dữ liệu có các ví dụ về văn bản đầu vào (prompt) và văn bản đầu ra lý tưởng mong đợi (nhãn), và tinh chỉnh mô hình để mô phỏng hành vi hoặc nhiệm vụ được ngụ ý từ những ví dụ này. Hãy xem cách thức hoạt động này.
Các tính năng tiêu biểu
Để minh họa việc tinh chỉnh mô hình, hãy xem xét một vấn đề phân loại sử dụng dữ liệu văn bản. Chúng ta sẽ sử dụng một tập dữ liệu chuyển đổi y tế và yêu cầu mô hình của chúng ta sẽ là phân loại một bản ghi nhất định vào một trong 17 danh mục, ví dụ như ‘Dị ứng/ Miễn dịch’, ‘Nha khoa’, ‘Tim mạch/ Phổi’, vv.
Dataset
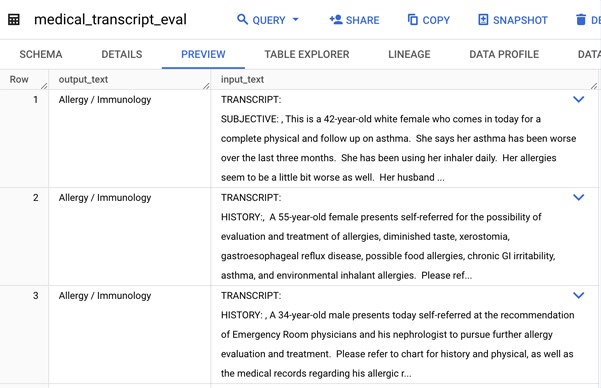
Tập dữ liệu của chúng ta được cung cấp trên Kaggle. Để tinh chỉnh và đánh giá mô hình này, trước tiên chúng ta sẽ tạo một bảng đánh giá và một bảng huấn luyện trong BigQuery bằng cách sử dụng một phần của dữ liệu này có sẵn trong Cloud Storage như sau:
— Create a eval table
LOAD DATA INTO
bqml_tutorial.medical_transcript_eval
FROM FILES( format=’NEWLINE_DELIMITED_JSON’,
uris = [‘gs://cloud-samples-data/vertex-ai/model-evaluation/peft_eval_sample.jsonl’] )
— Create a train table
LOAD DATA INTO
bqml_tutorial.medical_transcript_train
FROM FILES( format=’NEWLINE_DELIMITED_JSON’,
uris = [‘gs://cloud-samples-data/vertex-ai/model-evaluation/peft_train_sample.jsonl’] )
Bộ dữ liệu huấn luyện và đánh giá có một cột ‘input_text’ chứa bản ghi, và một cột ‘output_text’ chứa nhãn hoặc Ground truth.
Hiểu về hiệu suất cơ bản của mô hình text-bison
Trước hết, hãy xác định một điểm cơ bản về hiệu suất cho mô hình text-bison. Bạn có thể tạo một mô hình text-bison từ xa trong BigQuery bằng một câu lệnh SQL như câu lệnh dưới đây.
CREATE OR REPLACE MODEL
`bqml_tutorial.text_bison_001` REMOTE
WITH CONNECTION `LOCATION. ConnectionID`
OPTIONS (ENDPOINT =’text-bison@001′)
Để suy luận về mô hình, trước tiên Google xây dựng một prompt bằng cách kết hợp mô tả tác vụ cho mô hình và bảng điểm từ các bảng mà chính Google đã tạo. Sau đó, họ sử dụng chức năng ML.Generate_Text để có được đầu ra. Mặc dù mô hình nhận được nhiều phân loại chính xác, nhưng nó phân loại một số bảng điểm một cách sai lầm. Ở đây, một phản hồi mẫu trong đó phân loại không chính xác.
Prompt
Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. TRANSCRIPT:
INDICATIONS FOR PROCEDURE:, The patient has presented with atypical type right arm discomfort and neck discomfort. She had noninvasive vascular imaging demonstrating suspected right subclavian stenosis. Of note, there was bidirectional flow in the right vertebral artery, as well as 250 cm per second velocities in the right subclavian. Duplex ultrasound showed at least a 50% stenosis.,APPROACH:, Right common femoral artery.,ANESTHESIA:, IV sedation with cardiac catheterization protocol. Local infiltration with 1% Xylocaine.,COMPLICATIONS:, None.,ESTIMATED BLOOD LOSS:, Less than 10 ml.,ESTIMATED CONTRAST:, Less than 250 ml.,PROCEDURE PERFORMED:, Right brachiocephalic angiography, right subclavian angiography, selective catheterization of the right subclavian, selective aortic arch angiogram, right iliofemoral angiogram, 6 French Angio-Seal placement.,DESCRIPTION OF PROCEDURE:, The patient was brought to the cardiac catheterization lab in the usual fasting state. She was laid supine on the cardiac catheterization table, and the right groin was prepped and draped in the usual sterile fashion. 1% Xylocaine was infiltrated into the right femoral vessels. Next, a #6 French sheath was introduced into the right femoral artery via the modified Seldinger technique.,AORTIC ARCH ANGIOGRAM:, Next, a pigtail catheter was advanced to the aortic arch. Aortic arch angiogram was then performed with injection of 45 ml of contrast, rate of 20 ml per second, maximum pressure 750 PSI in the 4 degree LAO view.,SELECTIVE SUBCLAVIAN ANGIOGRAPHY:, Next, the right subclavian was selectively cannulated. It was injected in the standard AP, as well as the RAO view. Next pull back pressures were measured across the right subclavian stenosis. No significant gradient was measured.,ANGIOGRAPHIC DETAILS:, The right brachiocephalic artery was patent. The proximal portion of the right carotid was patent. The proximal portion of the right subclavian prior to the origin of the vertebral and the internal mammary showed 50% stenosis.,IMPRESSION:,1. Moderate grade stenosis in the right subclavian artery.,2. Patent proximal edge of the right carotid.
Response
Radiology
Trong trường hợp trên, phân loại chính xác nên là ‘tim mạch/ phổi.
Đánh giá dựa trên các chỉ số cho mô hình cơ sở để thực hiện một đánh giá mạnh mẽ hơn về hiệu suất của mô hình, bạn có thể sử dụng hàm ML.EVALUATE của BigQuery để tính toán các chỉ số về cách các phản ứng của mô hình so sánh với các phản ứng lý tưởng từ một tập dữ liệu thử nghiệm/đánh giá. Bạn có thể làm như sau:
— Evaluate base model
SELECT
*
FROM
ml.evaluate(MODEL bqml_tutorial.text_bison_001,
(
SELECT
CONCAT(“Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. “, input_text) AS input_text,
output_text
FROM
`bqml_tutorial.medical_transcript_eval` ),
STRUCT(“classification” AS task_type))
Trong mã trên, Google đã cung cấp một bảng đánh giá làm đầu vào và chọn ‘Phân loại‘ là loại tác vụ mà họ đánh giá mô hình. Google để lại các thông số suy luận khác theo mặc định của chúng nhưng chúng có thể được sửa đổi để đánh giá.
Các số liệu đánh giá được trả về được tính toán cho mỗi lớp (nhãn). Kết quả trông giống như sau:
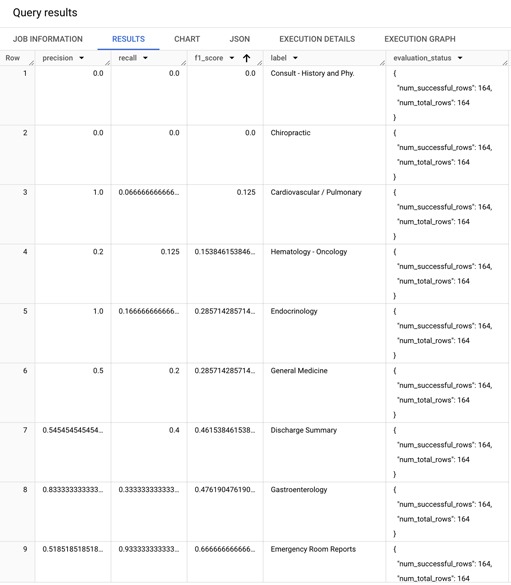
Tập trung vào điểm F1 (giá trị trung bình hòa của precision và recall), bạn có thể thấy rằng hiệu suất của mô hình thay đổi giữa các lớp. Ví dụ, mô hình cơ sở hoạt động tốt cho các lớp ‘Autopsy’, ‘Diets and Nutritions’, và ‘Dentistry’, nhưng hoạt động kém cho các lớp ‘Consult – History and Phy.’, ‘Chiropractic’, và ‘Cardiovascular / Pulmonary’.
Bây giờ hãy tinh chỉnh mô hình của chúng tôi và xem liệu chúng ta có thể cải thiện hiệu suất cơ sở này không.
Tạo một mô hình được tinh chỉnh
Việc tạo một mô hình được tinh chỉnh trong BigQuery là đơn giản. Bạn có thể thực hiện tinh chỉnh bằng cách chỉ định dữ liệu huấn luyện với các cột ‘prompt’ và ‘label’ trong câu lệnh Tạo Mô hình. Chúng ta sử dụng cùng một prompt để tinh chỉnh mà chúng ta đã sử dụng trong đánh giá trước đó. Tạo một mô hình được tinh chỉnh như sau:
— Fine tune a textbison model
CREATE OR REPLACE MODEL
`bqml_tutorial.text_bison_001_medical_transcript_finetuned` REMOTE
WITH CONNECTION `LOCATION. ConnectionID`
OPTIONS (endpoint=”text-bison@001″,
max_iterations=300,
data_split_method=”no_split”) AS
SELECT
CONCAT(“Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. “, input_text) AS prompt,
output_text AS label
FROM
`bqml_tutorial.medical_transcript_train`
CÁC KẾT NỐI bạn sử dụng để tạo mô hình được tinh chỉnh phải có (a) Storage Object User và (b) Vertex AI Service Agent roles. Ngoài ra, tài khoản dịch vụ mặc định của Compute Engine (GCE) của bạn phải có quyền chỉnh sửa đối với dự án. Tham khảo tài liệu để biết hướng dẫn về cách làm việc với các kết nối BigQuery.
BigQuery thực hiện việc tinh chỉnh mô hình bằng cách sử dụng một kỹ thuật được biết đến là Low-Rank Adaptation (LoRA). Việc điều chỉnh LoRA là một phương pháp điều chỉnh hiệu quả tham số (PET) mà đóng băng trọng số mô hình được đào tạo trước và ghi đè ma trận phân tách hạng có thể đào tạo vào mỗi lớp của kiến trúc Transformer để giảm số lượng tham số có thể đào tạo. Việc tinh chỉnh mô hình xảy ra trên một máy tính Vertex AI và bạn có thể chọn GPU hoặc TPU làm bộ gia tốc. Bạn sẽ được tính phí bởi BigQuery cho dữ liệu được quét hoặc khe cắm sử dụng, cũng như bởi Vertex AI cho các tài nguyên Vertex AI được tiêu thụ. Công việc tinh chỉnh tạo ra một điểm cuối mô hình mới đại diện cho các trọng số đã học. Các khoản phí dự đoán của Vertex AI mà bạn phải trả khi truy vấn mô hình được tinh chỉnh là giống như với mô hình cơ sở.
Công việc tinh chỉnh này có thể mất một vài giờ để hoàn thành, thay đổi dựa trên các tùy chọn huấn luyện như ‘max_iterations’. Sau khi hoàn thành, bạn có thể tìm thấy chi tiết của mô hình được tinh chỉnh của bạn trong giao diện người dùng BigQuery, nơi bạn sẽ thấy một điểm cuối từ xa khác cho mô hình được tinh chỉnh.

Hiện tại, BigQuery hỗ trợ việc tinh chỉnh của các mô hình text-bison-001 và text-bison-002.
Đánh giá hiệu xuất tinh chỉnh model
Bây giờ bạn có thể tạo dự đoán từ việc tinh chỉnh model sử dụng code như sau :
SELECT
ml_generate_text_llm_result,
label,
prompt
FROM
ml.generate_text(MODEL bqml_tutorial.text_bison_001_medical_transcript_finetuned,
(
SELECT
CONCAT(“Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. “, input_text) AS prompt,
output_text as label
FROM
`bqml_tutorial.medical_transcript_eval`
),
STRUCT(TRUE AS flatten_json_output))
Hãy xem xét phản hồi đối với prompt mẫu mà Google đã đánh giá trước đó. Sử dụng cùng một prompt, mô hình bây giờ phân loại bản ghi như ‘Cardiovascular / Pulmonary’ — phản hồi chính xác.
Đánh giá dựa trên chỉ số cho mô hình được tinh chỉnh
Bây giờ, chúng ta sẽ tính toán các chỉ số cho mô hình được tinh chỉnh bằng cách sử dụng cùng một dữ liệu đánh giá và cùng một prompt mà Google đã sử dụng trước đó để đánh giá mô hình cơ sở.
— Evaluate fine tuned model
SELECT
*
FROM
ml.evaluate(MODEL bqml_tutorial.text_bison_001_medical_transcript_finetuned,
(
SELECT
CONCAT(“Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. “, input_text) AS prompt,
output_text as label
FROM
`bqml_tutorial.medical_transcript_eval`), STRUCT(“classification” AS task_type))
Các chỉ số từ mô hình được tinh chỉnh được hiển thị dưới đây. Mặc dù tập dữ liệu tinh chỉnh (huấn luyện) mà Google sử dụng cho blog này chỉ chứa 519 ví dụ, chúng ta đã thấy một cải thiện đáng kể trong hiệu suất. Điểm F1 trên các nhãn, nơi mà mô hình đã hoạt động kém trước đây, đã được cải thiện, với điểm F1 “macro” (trung bình đơn giản của điểm F1 trên tất cả các nhãn) tăng từ 0,54 lên 0,66.

Sẵn sàng cho suy luận
Mô hình được tinh chỉnh bây giờ có thể được sử dụng cho việc suy luận bằng cách sử dụng hàm ML.GENERATE_TEXT, mà Google đã sử dụng trong các bước trước để có được các phản hồi mẫu. Bạn không cần quản lý bất kỳ cơ sở hạ tầng bổ sung nào cho mô hình được tinh chỉnh của bạn và bạn được tính giá suy luận giống như bạn đã phải chịu cho mô hình cơ sở.
Bài viết liên quan