

Trong quá trình vận hành, các chuỗi hoạt động như họp trực tuyến, đào tạo…
Introducing LLM fine-tuning and evaluation in BigQuery
BigQuery cho phép bạn phân tích dữ liệu của mình bằng cách sử dụng một loạt các mô hình ngôn ngữ lớn (LLMs) được lưu trữ trong Vertex AI bao gồm Gemini 1.0 Pro, Gemini 1.0 Pro Vision và text-bison. Các mô hình này hoạt động tốt cho nhiều nhiệm vụ như tóm tắt văn bản, phân tích tâm trạng, vv. chỉ bằng cách sử dụng kỹ thuật prompt. Tuy nhiên, trong một số tình huống, việc tinh chỉnh bổ sung thông qua việc tinh chỉnh mô hình là cần thiết, như khi hành vi mong đợi của mô hình khó mô tả một cách ngắn gọn trong một prompt, hoặc khi prompt không tạo ra kết quả mong đợi một cách đồng nhất đủ.
Fine-tuning also helps the model learn specific response styles (e.g., terse or verbose), new behaviors (e.g., answering as a specific persona), or to update itself with new information.
Today, we are announcing support for customizing LLMs in BigQuery with supervised fine-tuning. Supervised fine-tuning via BigQuery uses a dataset which has examples of input text (the prompt) and the expected ideal output text (the label), and fine-tunes the model to mimic the behavior or task implied from these examples.Let’s see how this works.
Feature walkthrough
To illustrate model fine-tuning, let’s look at a classification problem using text data. We’ll use a medical transcription dataset and ask our model to classify a given transcript into one of 17 categories, e.g. ‘Allergy/Immunology’, ‘Dentistry’, ‘Cardiovascular/ Pulmonary’, etc.
Dataset
Our dataset is from cung cấp trên Kaggle. To fine-tune and evaluate our model, we first create an evaluation table and a training table in BigQuery using a subset of this data available in Cloud Storage as follows:
— Create a eval table
LOAD DATA INTO
bqml_tutorial.medical_transcript_eval
FROM FILES( format=’NEWLINE_DELIMITED_JSON’,
uris = [‘gs://cloud-samples-data/vertex-ai/model-evaluation/peft_eval_sample.jsonl’] )
— Create a train table
LOAD DATA INTO
bqml_tutorial.medical_transcript_train
FROM FILES( format=’NEWLINE_DELIMITED_JSON’,
uris = [‘gs://cloud-samples-data/vertex-ai/model-evaluation/peft_train_sample.jsonl’] )
The training and evaluation dataset has an ‘input_text’ column that contains the transcript, and a ‘output_text’ column that contains the label, or ground truth.
Baseline performance of text-bison model
First, let’s establish a performance baseline for the text-bison model. You can create a remote text-bison model in BigQuery using a SQL statement like the one below.
CREATE OR REPLACE MODEL
`bqml_tutorial.text_bison_001` REMOTE
WITH CONNECTION `LOCATION. ConnectionID`
OPTIONS (ENDPOINT =’text-bison@001′)
For inference on the model, we first construct a prompt by concatenating the task description for our model and the transcript from the tables we created. We then use the ML.Generate_Text function to get the output. While the model gets many classifications correct out of the box, it classifies some transcripts erroneously. Here’s a sample response where it classifies incorrectly.
Prompt
Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. TRANSCRIPT:
INDICATIONS FOR PROCEDURE:, The patient has presented with atypical type right arm discomfort and neck discomfort. She had noninvasive vascular imaging demonstrating suspected right subclavian stenosis. Of note, there was bidirectional flow in the right vertebral artery, as well as 250 cm per second velocities in the right subclavian. Duplex ultrasound showed at least a 50% stenosis.,APPROACH:, Right common femoral artery.,ANESTHESIA:, IV sedation with cardiac catheterization protocol. Local infiltration with 1% Xylocaine.,COMPLICATIONS:, None.,ESTIMATED BLOOD LOSS:, Less than 10 ml.,ESTIMATED CONTRAST:, Less than 250 ml.,PROCEDURE PERFORMED:, Right brachiocephalic angiography, right subclavian angiography, selective catheterization of the right subclavian, selective aortic arch angiogram, right iliofemoral angiogram, 6 French Angio-Seal placement.,DESCRIPTION OF PROCEDURE:, The patient was brought to the cardiac catheterization lab in the usual fasting state. She was laid supine on the cardiac catheterization table, and the right groin was prepped and draped in the usual sterile fashion. 1% Xylocaine was infiltrated into the right femoral vessels. Next, a #6 French sheath was introduced into the right femoral artery via the modified Seldinger technique.,AORTIC ARCH ANGIOGRAM:, Next, a pigtail catheter was advanced to the aortic arch. Aortic arch angiogram was then performed with injection of 45 ml of contrast, rate of 20 ml per second, maximum pressure 750 PSI in the 4 degree LAO view.,SELECTIVE SUBCLAVIAN ANGIOGRAPHY:, Next, the right subclavian was selectively cannulated. It was injected in the standard AP, as well as the RAO view. Next pull back pressures were measured across the right subclavian stenosis. No significant gradient was measured.,ANGIOGRAPHIC DETAILS:, The right brachiocephalic artery was patent. The proximal portion of the right carotid was patent. The proximal portion of the right subclavian prior to the origin of the vertebral and the internal mammary showed 50% stenosis.,IMPRESSION:,1. Moderate grade stenosis in the right subclavian artery.,2. Patent proximal edge of the right carotid.
Response
Radiology
In the above case the correct classification should have been ‘Cardiovascular/ Pulmonary’
Metrics-based evaluation for base model To perform a more robust evaluation of the model’s performance, you can use BigQuery’s ML.EVALUATE function to compute metrics on how the model responses compare against the ideal responses from a test/eval dataset. You can do so as follows:
— Evaluate base model
SELECT
*
FROM
ml.evaluate(MODEL bqml_tutorial.text_bison_001,
(
SELECT
CONCAT(“Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. “, input_text) AS input_text,
output_text
FROM
`bqml_tutorial.medical_transcript_eval` ),
STRUCT(“classification” AS task_type))
In the above code we provided an evaluation table as input and chose ‘classification‘ as the task type on which we evaluate the model. We left other inference parameters at their defaults but they can be modified for the evaluation.
The evaluation metrics that are returned are computed for each class (label). The results look like following:
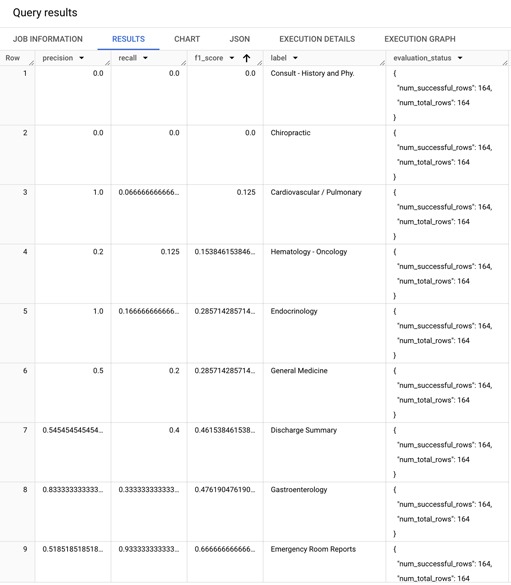
Focusing on the F1 Score (harmonic mean of precision and recall), you can see that the model performance varies between classes. For example, the baseline model performs well for ‘Autopsy’, ‘Diets and Nutritions’, and ‘Dentistry’, but performs poorly for ‘Consult - History and Phy.’, ‘Chiropractic’, and ‘Cardiovascular / Pulmonary’ classes.
Now let’s fine-tune our model and see if we can improve on this baseline performance.
Creating a fine-tuned model
Creating a fine-tuned model in BigQuery is simple. You can perform fine-tuning by specifying the training data with ‘prompt’ and ‘label’ columns in it in the Create Model statement. We use the same prompt for fine-tuning that we used in the evaluation earlier. Create a fine-tuned model as follows:
— Fine tune a textbison model
CREATE OR REPLACE MODEL
`bqml_tutorial.text_bison_001_medical_transcript_finetuned` REMOTE
WITH CONNECTION `LOCATION. ConnectionID`
OPTIONS (endpoint=”text-bison@001″,
max_iterations=300,
data_split_method=”no_split”) AS
SELECT
CONCAT(“Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. “, input_text) AS prompt,
output_text AS label
FROM
`bqml_tutorial.medical_transcript_train`
The CONNECTION you use to create the fine-tuned model should have (a) Storage Object User and (b) Vertex AI Service Agent roles attached. In addition, your Compute Engine (GCE) default service account should have an editor access to the project. Refer to the document for guidance on working with BigQuery connections.
BigQuery performs model fine-tuning using a technique known as Low-Rank Adaptation (LoRA. LoRA tuning is a parameter efficient tuning (PET) method that freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture to reduce the number of trainable parameters. The model fine-tuning itself happens on a Vertex AI compute and you have the option to choose GPUs or TPUs as accelerators. You are billed by BigQuery for the data scanned or slots used, as well as by Vertex AI for the Vertex AI resources consumed. The fine-tuning job creates a new model endpoint that represents the learned weights. The Vertex AI inference charges you incur when querying the fine-tuned model are the same as for the baseline model.
This fine-tuning job may take a couple of hours to complete, varying based on training options such as ‘max_iterations’. Once completed, you can find the details of your fine-tuned model in the BigQuery UI, where you will see a different remote endpoint for the fine-tuned model.

Currently, BigQuery supports fine-tuning of text-bison-001 and text-bison-002 models.
Evaluating performance of fine-tuned model
You can now generate predictions from the fine-tuned model using code such as following:
SELECT
ml_generate_text_llm_result,
label,
prompt
FROM
ml.generate_text(MODEL bqml_tutorial.text_bison_001_medical_transcript_finetuned,
(
SELECT
CONCAT(“Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. “, input_text) AS prompt,
output_text as label
FROM
`bqml_tutorial.medical_transcript_eval`
),
STRUCT(TRUE AS flatten_json_output))
Let us look at the response to the sample prompt we evaluated earlier. Using the same prompt, the model now classifies the transcript as ‘Cardiovascular / Pulmonary’ — the correct response.
Metrics based evaluation for fine tuned model
Now, we will compute metrics on the fine-tuned model using the same evaluation data and the same prompt we previously used for evaluating the base model.
— Evaluate fine tuned model
SELECT
*
FROM
ml.evaluate(MODEL bqml_tutorial.text_bison_001_medical_transcript_finetuned,
(
SELECT
CONCAT(“Please assign a label for the given medical transcript from among these labels [Allergy / Immunology, Autopsy, Bariatrics, Cardiovascular / Pulmonary, Chiropractic, Consult – History and Phy., Cosmetic / Plastic Surgery, Dentistry, Dermatology, Diets and Nutritions, Discharge Summary, ENT – Otolaryngology, Emergency Room Reports, Endocrinology, Gastroenterology, General Medicine, Hematology – Oncology, Hospice – Palliative Care, IME-QME-Work Comp etc., Lab Medicine – Pathology, Letters, Nephrology, Neurology, Neurosurgery, Obstetrics / Gynecology, Office Notes, Ophthalmology, Orthopedic, Pain Management, Pediatrics – Neonatal, Physical Medicine – Rehab, Podiatry, Psychiatry / Psychology, Radiology, Rheumatology, SOAP / Chart / Progress Notes, Sleep Medicine, Speech – Language, Surgery, Urology]. “, input_text) AS prompt,
output_text as label
FROM
`bqml_tutorial.medical_transcript_eval`), STRUCT(“classification” AS task_type))
metrics from the fine-tuned model are below. Even though the fine-tuning (training) dataset we used for this blog contained only 519 examples, we already see a marked improvement in performance. F1 scores on the labels, where the model had performed poorly earlier, have improved, with the “macro” F1 score (a simple average of F1 score across all labels) jumping from 0.54 to 0.66.

Ready for inference
The fine-tuned model can now be used for inference using the ML.GENERATE_TEXT function, which we used in the previous steps to get the sample responses. You don’t need to manage any additional infrastructure for your fine-tuned model and you are charged the same inference price as you would have incurred for the base model.
Related Posts


