
Google xin giới thiệu Veo 3.1 Lite, mô hình video tiết kiệm chi phí nhất…
Kiến trúc dự phòng thảm họa cơ sở dữ liệu đa vùng cho MySQL
Các doanh nghiệp mong đợi độ tin cậy cao của cơ sở hạ tầng lưu trữ dữ liệu mà ứng dụng của họ đang sử dụng. Mặc dù của bạn và đội ngũ chuẩn bị những kịch bản kỹ thuật tốt nhất, cẩn thận, những vẫn có rủi ro xảy ra lỗi cơ sở dữ liệu, cho dù máy chủ đó hay phân vùng mạng có bị lỗi hay không. Lập kế hoạch tốt có thể giúp bạn ứng phó trước các vấn đề và phục hồi nhanh hơn khi có thảm họa xảy ra.
Blog này cho thấy một cách tiếp cận triển khai kiến trúc cơ sở dữ liệu đảm bảo khả năng phục hồi và khắc phục thảm họa cao cho MySQL trên Compute Engine, sử dụng các đĩa khu vực cũng như các bộ cân bằng tải.
Bất kỳ kiến trúc cơ sở dữ liệu nào cũng phải chuẩn bị sẵn các cách tiếp cận để khắc phục lỗi và phục hồi nhanh chóng khi có lỗi mà không mất dữ liệu. Các phương pháp này được thể hiện trong RTO (recovery time objective) và RPO (recovery point objective), đưa ra các cách để thiết lập và sau đó đo thời gian dịch vụ có thể không khả dụng và lưu dữ liệu sẽ được lưu lại bao xa.
Khi một cơ sở dữ liệu bị lỗi, chúng phải được phục hồi nhanh nhất có thể với RTO càng nhỏ càng tốt, lý tưởng là trong vài giây. Phải mất ít dữ liệu nhất có thể, thậm chí không mất gì cả. RPO mong muốn là trạng thái cơ sở dữ liệu nhất quán cuối cùng.
Từ một kiến trúc cơ sở dữ liệu và thiết kế triển khai, điều này có thể được thực hiện với hai khái niệm riêng biệt: tính sẵn sàng cao và khả năng khắc phục thảm họa. Sử dụng cả hai cùng một lúc để đạt được một kiến trúc mà Chuẩn bị cho phạm vi lỗi hoặc sự cố lớn nhất.
Tạo một kiến trúc cơ sở dữ liệu linh hoạt
Một kiến trúc cơ sở dữ liệu có tính sẵn sàng cao có các máy chủ cơ sở dữ liệu tại ít nhất hai hoặc nhiều vùng. Nếu một máy chủ trên một vùng bị lỗi hoặc vùng đó không thể truy cập được, thì các dữ liệu ở các vùng khác cũng luôn sẵn sàng để tiếp tục xử lý. Hình dưới đây cho thấy hai trường hợp, một trong khu vực zn1 và một trong khu vực zn2. Bộ cân bằng tải ở phía trước hỗ trợ điều hướng lưu lượng đến một cơ sở dữ liệu ‘khỏe nhất’ có sẵn để đọc và ghi truy vấn.
Một kiến trúc phục hồi thảm họa bổ sung một thiết lập cơ sở dữ liệu sẵn sàng cao thứ hai trong khu vực thứ hai. Nếu một trong các khu vực trở nên không thể truy cập hoặc thất bại, khu vực khác sẽ lập tức được đưa vào sử dụng. Hình dưới đây cho thấy hai khu vực, khu vực chính và khu vực DR (phục hồi sau thảm họa). Dữ liệu được sao chép từ vùng chính sang vùng DR để vùng DR có thể tiếp quản từ trạng thái cơ sở dữ liệu nhất quán mới nhất. Bộ cân bằng tải ở phía trước các vùng sẽ điều hướng lưu lượng đến vùng chịu trách nhiệm về lưu lượng đọc và ghi. Đây là cách mà kiến trúc này trông như thế nào:
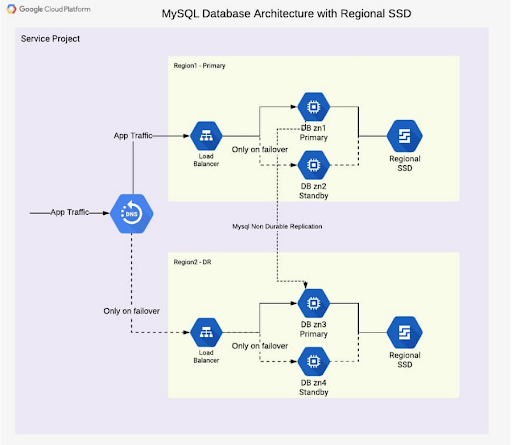
Ngoài thiết lập các máy chủ cơ sở dữ liệu, cũng cần thiết triển khai một ổ đĩa khu vực (regional) được ghi đồng thời ở hai vùng (hai zone), nhằm đảm bảo an toàn trong trường hợp xảy ra lỗi ở vùng nào đó. Đây là một lợi thế rất lớn của Google Cloud, cho phép bạn bỏ qua việc sao chép cấp độ MySQL trong một khu vực. Mỗi thao tác ghi vào đĩa được thực hiện đồng bộ trong hai vùng. Khi máy chủ chính gặp sực cố, một máy chủ dự phòng được gắn với (các) đĩa trong khu vực và dịch vụ cơ sở dữ liệu (MySQL) sau đó được bắt đầu sử dụng tương tự. Điều này mang lại sự an tâm khi không lo lắng về độ trễ sao chép hoặc trạng thái cơ sở dữ liệu cho tính sẵn sàng cao.
Từ quan điểm quá trình khắc phục thảm họa, những điều sau đây xảy ra theo thời gian khi có sự cố:
- Hoạt động cơ sở dữ liệu trạng thái ổn định bình thường
- Một lỗi xảy ra và một khu vực trở nên không thể hoạt động hoặc trường hợp cơ sở dữ liệu không thể truy cập
- Phải quyết định xem hệ thống có bị ‘chết’ hay không (trong trường hợp kỳ vọng rằng khu vực sẽ sớm hoạt động trở lại hoặc máy chủ trở lại hoạt động).
- DNS được cập nhật thủ công, do đó nó chuyển hướng lưu lượng truy cập ứng dụng đến khu vực thứ hai
- Khôi phục lại hoạt động tại khu vực chính sau khi máy chủ bình thường trở lại (tùy chọn), vì khu vực thứ hai cũng đã được triển khai, xây dựng đầy đủ
Từ quan điểm quy trình có tính sẵn sàng cao, những điều sau đây có thể xảy ra theo thời gian trong nhiều tình huốngi:
- Hoạt động cơ sở dữ liệu trạng thái ổn định bình thường
- Máy chủ Database không hoạt động
- Khởi động máy chủ dự phòng
- Mount regional SSD và kích hoạt database
- Tự động chuyển hướng lưu lượng ứng dụng sang chế độ chờ thông qua bộ cân bằng tải
- Sau khi máy chủ gặp sự cố hoặc không sẵn sàng trở lại, có sử dụng hệ thống dự phòng hay không
Kiến trúc cơ sở dữ liệu có tính khả dụng cao sẽ hỗ trợ khắc phục thảm họa. Với các đĩa khu vực và bộ cân bằng tải, thật đơn giản để triển khai cơ sở dữ liệu linh hoạt.
Xem thêm về load balancers và regional disks, quy trình HA và DR, các bước làm chi tiết trong phần đầu của tài liệu này. Hãy thử để làm quen với kiến trúc cũng như quá trình chuyển đổi dự phòng.
Nguồn: Gimasys
Bài viết liên quan


