Tư duy ưu tiên bảo mật của Google xuất phát từ hơn hai thập kỷ…
Tối ưu BigQuery với nguồn dữ liệu trong Google Cloud VMware Engine

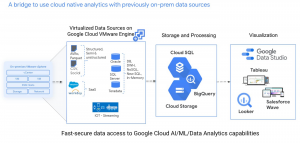
Dành cho những khách hàng đã di chuyển các nguồn dữ liệu tại hệ thống on-premise sang Google Cloud VMware Engine (https://cloud.google.com/vmware-engine) và muốn sử dụng các dịch vụ phân tích và dữ liệu do Google Cloud cung cấp. Một trong những mục tiêu của những khách hàng chọn Google Cloud là tận dụng phân tích Google Cloud với tập dữ liệu của họ. Nếu bạn là người ra quyết định về IT hoặc kiến trúc sư dữ liệu muốn nhanh chóng sử dụng sức mạnh dữ liệu của mình với Google analytics, blog này mô tả các phương pháp truy cập dữ liệu của bạn trong BigQuery, nơi có thể thực hiện phân tích nâng cao và machine learning trên bộ dữ liệu của bạn.
> Tham khảo:
- Giới thiệu Datastream cho Google BigQuery
- Phân tích khối dữ liệu lớn với BigQuery và Google Sheets
- Cách di chuyển kho dữ liệu on premises sang BigQuery trên Google Cloud
Tại sao?
Tiêu thụ và phân tích dữ liệu đi đầu trong công nghệ. Khách hàng ngày nay sử dụng và quản lý một lượng lớn dữ liệu và nguồn tài nguyên. Những thách thức này tạo cơ hội cho Google Cloud hỗ trợ quản lý và hiểu cơ sở dữ liệu hiện có của bạn mà không cần phải tái kiến trúc tốn kém tài liệu nguồn hoặc vị trí dữ liệu của bạn. Blog này trình bày các cách tiếp cận để truy cập dữ liệu Google Cloud và các dịch vụ phân tích bằng dữ liệu hiện có của bạn mà không cần phải kiến trúc lại cơ sở dữ liệu của bạn. Sau khi các nguồn dữ liệu của bạn nằm trong Google Cloud VMware Engine, cơ sở hạ tầng có khả năng chịu lỗi cao và khả dụng của Google có thể được tận dụng để nâng cao hiệu suất của các data pipeline. Các giải pháp này nhằm mục đích giảm thời gian trích xuất giá trị từ tập dữ liệu của bạn với phân tích gốc đám mây có sẵn thông qua BigQuery.
Giải pháp di chuyển qua Google Cloud VMware Engine này mang lại lợi thế cho tất cả các phần của hoạt động dữ liệu. Người quản trị cơ sở dữ liệu (DBA) và cơ sở hạ tầng ảo / quản trị viên đám mây có thể sử dụng các môi trường quen thuộc tương tự như tại chỗ trên đám mây. Nhóm cơ sở hạ tầng tại chỗ có thể cho phép nhóm nhà khoa học dữ liệu / AI / machine learning (ML) sử dụng các bộ công cụ quen thuộc. Các nhóm này hiện có quyền truy cập vào Google Cloud AI / ML / khả năng phân tích dữ liệu cho dữ liệu tại chỗ của họ.
Ví dụ: nếu bạn muốn khám phá các cơ hội bán kèm trong các sản phẩm của mình, thì bước đầu tiên là đảm bảo rằng tập dữ liệu thanh toán và sử dụng sản phẩm trên các sản phẩm của bạn được kết nối để phân tích. Nhóm DBA sẽ xác định các tập dữ liệu này và nhóm cơ sở hạ tầng sẽ cho phép truy cập vào các nguồn này. Sau đó, nhóm ứng dụng sẽ sao chép dữ liệu này sang BigQuery và sử dụng các phương pháp tiếp cận như BigQuery ML Recommendations (https://cloud.google.com/bigquery-ml/docs/bigqueryml-mf-explicit-tutorial) để khám phá các cơ hội bán kèm. Một ví dụ khác về trường hợp sử dụng là dự báo mức tăng trưởng sử dụng cho các hoạt động và lập kế hoạch tăng trưởng. Sau khi dữ liệu bán hàng của bạn được sao chép trong BigQuery, các phương pháp nâng cao dự báo chuỗi thời gian sẽ khả dụng với tập dữ liệu của bạn.
Điều này bao gồm những gì?
Các phương pháp tái tạo tập dữ liệu quan hệ của bạn trong BigQuery theo cách riêng tư và an toàn bằng cách sử dụng Google Cloud Data Fusion (https://cloud.google.com/data-fusion/) hoặc Google Cloud Datastream (https://cloud.google.com/datastream). Datafusion là một công cụ ETL hỗ trợ nhiều loại data pipeline khác nhau. Datastream là một dịch vụ để thu thập và nhân rộng dữ liệu thay đổi. Sử dụng cả hai dịch vụ này, dữ liệu luôn nằm trong các dự án của bạn trong Google Cloud và IP nội bộ được sử dụng để truy cập dữ liệu. Chúng tôi sẽ tập trung vào sao chép theo thời gian thực để bạn có thể truy cập dữ liệu của mình liên tục từ các kho dữ liệu hoạt động, chẳng hạn như SQL Server, MySQL và Oracle trong BigQuery.
Di chuyển dữ liệu từ các nguồn dữ liệu của bạn lên đám mây và duy trì data pipeline đến kho dữ liệu của bạn thông qua Trích xuất (Extract) – chuyển đổi (Transform) – tải (Load) (ETL) là một hoạt động tốn nhiều thời gian. Một cách tiếp cận thay thế là ELT (Extract Load Transform). Phương pháp ELT tải dữ liệu vào hệ thống đích (ví dụ: BigQuery) trước khi chuyển đổi dữ liệu. Quy trình ELT thường được ưa thích hơn quy trình ETL truyền thống vì nó đơn giản hơn để nhận ra và tải dữ liệu nhanh hơn.
Với các tập dữ liệu của bạn hiện nằm trong Google Cloud, các nhóm dữ liệu có thể sử dụng Cloud Data Fusion và Datastream qua mạng Google Cloud tốc độ cao, độ trễ thấp để sao chép hoặc di chuyển dữ liệu từ cơ sở hạ tầng VMware của bạn đến các điểm đến khác nhau trong Google Cloud Platform, chẳng hạn như Google Cloud native Storage buckets hoặc BigQuery.
Để đơn giản, trong bài viết sẽ giả định rằng tất cả các dịch vụ được sử dụng trong cùng một dự án. Và chúng ta cũng sẽ thảo luận về một số ý nghĩa về giá khi di chuyển dữ liệu từ Google Cloud VMware Engine từ tại chỗ hoặc một đám mây riêng ảo khác (VPC).

Cloud Data Fusion:
Cloud Data Fusion cung cấp giao diện điểm và nhấp trực quan cho phép triển khai data pipeline ETL / ELT mà không cần code. Cloud Data Fusion cũng cung cấp một trình tăng tốc sao chép cho phép bạn sao chép các bảng của mình vào BigQuery.
Cloud Data Fusion nội bộ thiết lập một dự án đối tượng thuê với các VPC của riêng nó để quản lý tài nguyên của Cloud Data Fusion. Để truy cập các nguồn dữ liệu trong Google Cloud VMware Engine bằng Cloud Data Fusion, chúng tôi sử dụng proxy ngược trên VPC chính. Điều này được mô tả trong hình ảnh dưới đây.
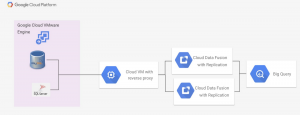
Trong trường hợp này, Google có khối lượng công việc dữ liệu của mình đang chạy trên phiên bản Google Cloud VMware Engine trong dự án. Môi trường Google Cloud VMware Engine được truy cập thông qua VPC cấp dự án ngang hàng với Google Cloud VMware Engine. Phiên bản Google Compute Engine ở cấp dự án VPC cho thấy proxy ngược đối với cơ sở dữ liệu Google Cloud VMware Engine cho các dịch vụ không thể truy cập trực tiếp vào phiên bản Google Cloud VMware Engine. Phiên bản Cloud Data Fusion được kích hoạt với quyền truy cập IP riêng và mạng ngang hàng với VPC chính và có thể truy cập dữ liệu thông qua phiên bản proxy ngược. Quy trình thiết lập quyền truy cập IP nội bộ và mạng ngang hàng trên Cloud Data Fusion được mô tả trong tài liệu này.
Khi quá trình ngang hàng này hoàn tất, sử dụng trình kết nối Java Database Connectivity trong Cloud Data Fusion để truy cập cơ sở dữ liệu của chúng tôi để nhân rộng hoặc cho các hoạt động ETL nâng cao. Để bật tính năng thu thập dữ liệu thay đổi, chúng tôi cần bật cơ sở dữ liệu trong Google Cloud VMware Engine để theo dõi và nắm bắt các thay đổi đối với cơ sở dữ liệu. Toàn bộ quá trình thiết lập và nhân rộng này được mô tả trong tài liệu dành cho MySQL (https://cloud.google.com/data-fusion/docs/tutorials/replicating-data/mysql-to-bigquery) và SQL Server.
Google Cloud Datastream:
Datastream là một dịch vụ sao chép và thu thập dữ liệu thay đổi không cần máy chủ. Bạn có thể truy cập dữ liệu phát trực tuyến, độ trễ thấp từ cơ sở dữ liệu Oracle và MySQL trên Google Cloud VMware Engine. Cách tiếp cận này mang lại sự linh hoạt hơn trong việc quản lý các data flow pipeline. Giải pháp này hiện đang được cung cấp trước chung và chỉ khả dụng ở một số khu vực nhất định.
Tùy chọn này cũng yêu cầu proxy ngược được cấu hình trong phiên bản Google Compute Engine. Proxy đảo ngược này được sử dụng để truy cập các nguồn dữ liệu trong Google Cloud VMware Engine. Tùy chọn này được mô tả trong tài liệu này
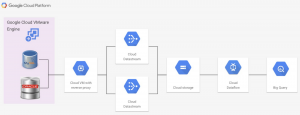
Bạn có thể tìm thấy thiết lập hoàn chỉnh để sử dụng Datastream trong hướng dẫn cách thực hiện này. Để kích hoạt tính năng sao chép, chúng ta cần một luồng được cấu hình trên Datastream, luồng này truy cập dữ liệu từ cơ sở dữ liệu và chuyển dữ liệu đến bộ lưu trữ đám mây. Dòng dữ liệu truy cập dữ liệu bằng proxy ngược cần được hiển thị trên VPC của khách hàng. Để chuyển dữ liệu đến BigQuery, sử dụng pre-configured mẫu Datastream đến BigQuery trong Dataflow.
Làm thế nào để bắt đầu?
Bước đầu tiên là di chuyển khối lượng công việc sang Google Cloud VMware Engine. Quản trị viên / kiến trúc sư đám mây của bạn thường sẽ thúc đẩy điều này. Nếu chưa được xác định trong giai đoạn di chuyển, bước tiếp theo là xác định cơ sở dữ liệu nằm trên các máy ảo được lưu trữ trong Google Cloud VMware Engine và tạo lại các báo cáo hiện có bằng BigQuery. Trong hầu hết các tổ chức sẽ có nhiều cá nhân tham gia vào quá trình này. Ví dụ: một kiến trúc sư dữ liệu có thể là nguồn tốt nhất để biết thông tin về các nguồn dữ liệu, một kiến trúc sư giải pháp sẽ có những hiểu biết sâu sắc về chi phí / hiệu suất và các đầu vào cơ sở hạ tầng sẽ cần thiết cho các giao diện mạng. Các bước dưới đây phác thảo một cách tiếp cận khả thi để kích hoạt chuyển động này.
- Xác định các tập dữ liệu nằm trên các máy ảo được di chuyển sang Google Cloud VMware Engine được sử dụng cho các báo cáo.
- Chọn pipeline phù hợp (Datastream so với Data Fusion) dựa trên loại cơ sở dữ liệu và các yêu cầu của pipeline (đánh đổi giá / hiệu suất và tính dễ sử dụng).
- Dựa trên data pipeline, chọn vùng thích hợp. Không có phí xuất dữ liệu trong cùng một khu vực.
- Thiết lập proxy ngược cho tập dữ liệu Google Cloud VMware Engine.
- Thiết lập dịch vụ sao chép với các tham số hiệu suất dựa trên hiệu suất sao chép cần thiết.
- Bật phân tích và trực quan hóa dựa trên các yêu cầu nghiệp vụ trên tập dữ liệu.
Kết luận:
Dịch vụ Google Cloud VMware Engine là một cách nhanh chóng và dễ dàng để kích hoạt tính năng trực quan hóa dữ liệu và phân tích bằng cách sử dụng các tập dữ liệu hiện có của bạn. Giờ đây, bạn có thể tận dụng tư thế hoạt động cơ sở hạ tầng hiện có của mình trên VMware để kích hoạt phân tích đám mây mà không phải mất thời gian tái cấu trúc cơ sở dữ liệu. Những cách tiếp cận này cho phép bạn tận dụng lợi ích hiệu suất của phần cứng chuyên dụng trên Google Cloud, kết nối với các khả năng dữ liệu tiên tiến nhất trên thế giới.
Nguồn: gcloudvn.com
Bài viết liên quan