Ngày 02/04 vừa qua, hội thảo trực tuyến do Gimasys phối hợp cùng Google Cloud…
Làm thế nào để xây dựng RAG pipelines trong Google BigQuery với Document AI Layout Parser
Document preprocessing (Xử lý trước tài liệu) là một trở ngại phổ biến khi xây dựng các đường ống retrieval-augmented generation (RAG). Nó thường đòi hỏi các kỹ năng python và các thư viện bên ngoài để phân tích các tài liệu như PDF thành các khối có thể quản lý và có thể được sử dụng để tạo ra các embeddings. Và ở bài viết này, Gimasys sẽ giúp bạn khai thác tối đa giá trị từ kho tài liệu khổng lồ của mình cũng như khám phá cách Google giúp bạn chuyển đổi những tài liệu phức tạp thành dữ liệu có cấu trúc, sẵn sàng phục vụ cho các mô hình AI.
Xử lý Streamline Document trong BigQuery
BigQuery Bây giờ cung cấp khả năng tiền xử lý trước tài liệu cho các Rag pipeline và các ứng dụng tập trung vào tài liệu khác thông qua việc tích hợp chặt chẽ với Document AI. Hàm ML.PROCESS_DOCUMENT có thể giúp bạn truy cập các bộ xử lý mới, bao gồm cả Document AI ‘ Layout Parser processor, cho phép bạn phân tích các tài liệu PDF với cú pháp SQL..
GA của ML.PROCESS_DOCUMENT cung cấp cho các nhà phát triển những lợi ích mới:
- Khả năng mở rộng được cải thiện: Khả năng xử lý các tài liệu lớn hơn lên đến 100 trang và xử lý chúng nhanh hơn
- Cú pháp đơn giản hóa: Cú pháp SQL được sắp xếp hợp lý để tương tác với Document AI ‘ Layout Parser processor
- Tài liệu bổ sung: Truy cập vào tài liệu bổ sung với khả năng của bộ xử lý AI như trình phân tích cú pháp Bố cục, để tạo các khối tài liệu cần thiết cho các RAG pipeline
Cụ thể, tài liệu bổ sung là một thành phần quan trọng, nhưng đầy thách thức của việc xây dựng một Rag pipeline. Trình phân tích cú pháp trong tài liệu AI sẽ giúp đơn giản hóa quá trình này.
Document preprocessing cho RAG
Chia các tài liệu lớn thành các đơn vị nhỏ hơn, liên quan đến ngữ cảnh giúp cải thiện mức độ liên quan của thông tin được truy xuất, dẫn đến câu trả lời chính xác hơn từ mô hình ngôn ngữ lớn (LLM).
Tạo siêu dữ liệu từ nguồn tài liệu, vị trí và thông tin cấu trúc cùng với các khối có thể củng cố hơn nữa RAG pipeline của bạn, giúp bạn lọc, tinh chỉnh kết quả tìm kiếm và gỡ lỗi cho mã.
Biểu đồ sau đây cung cấp một cái nhìn tổng quan về các bước xử lý trong một Rag pipeline cơ bản:
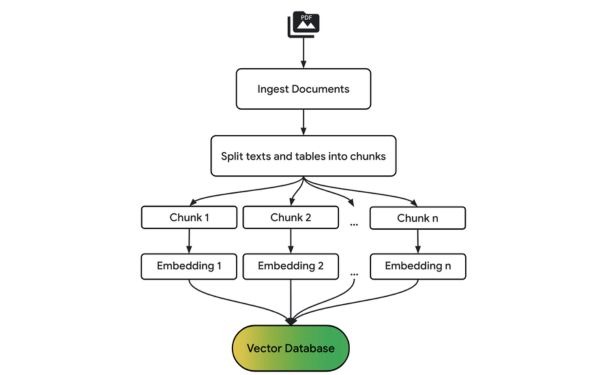
Xây dựng một RAG pipeline trong BigQuery
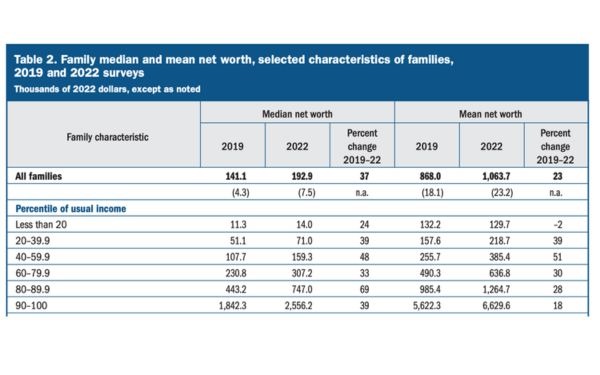
So sánh các tài liệu tài chính như báo cáo thu nhập có thể là một thách thức do cấu trúc phức tạp và sự pha trộn giữa văn bản, số liệu và bảng biểu. Các nhà báo cáo đã thử mô tả cách xây dựng một Rag pipeline trong BigQuery bằng cách sử dụng Document AI’s Layout Parser để phân tích Survey of Consumer Finances (SCF) report 2023 của Cục Dự trữ liên bang Mỹ.
Các tài liệu tài chính dày đặc như báo cáo SCF của Cục Dự trữ Liên bang đã đưa ra những thách thức quan trọng đối với các kỹ thuật phân tích truyền thống. Tài liệu này kéo dài gần 60 trang và chứa hỗn hợp văn bản, bảng biểu và biểu đồ nhúng, gây khó khăn cho việc trích xuất thông tin một cách đáng tin cậy. Document AI layout parser sẽ giúp bạn xử lý đống tài liệu đó 1 cách nhanh chóng, xác định hiệu quả và trích xuất thông tin chính từ các bố cục tài liệu phức tạp.
Xây dựng một Rag pipeline với Document AI layout parser bao gồm các bước sau.
Tạo Layout Parser processor
Trong Document AI, Tạo processor mới với LAYOUT_PARSER_PROCESSOR. Sau đó tạo một remote model trong BigQuery chỉ vào bộ xử lý này, cho phép BigQuery truy cập và xử lý các tài liệu.
Gọi processor để tạo chunks
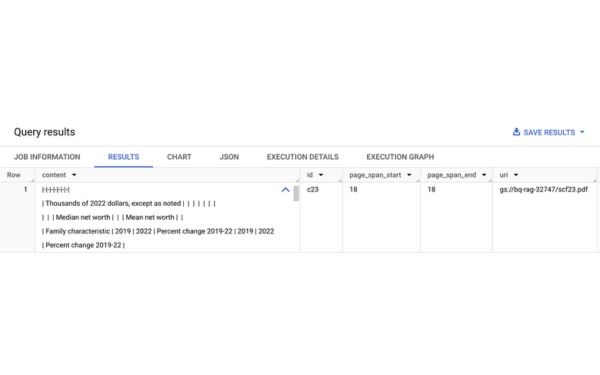
Để truy cập vào file PDFs trong Google Cloud Storage, bạn cần bắt đầu bằng cách tạo một bảng đối tượng trên bucket với các báo cáo thu nhập. Sau đó, sử dụng chức năng ML.PROCESS_DOCUMENT để truyền các đối tượng qua để AI ghi lại và trả về kết quả trong BigQuery. Document AI phân tích tài liệu và khối pdf. Các kết quả được trả về dưới dạng các đối tượng JSON và có thể dễ dàng được phân tích cú pháp để trích xuất siêu dữ liệu như URI nguồn và số trang.
SELECT * FROM ML.PROCESS_DOCUMENT(
MODEL docai_demo.layout_parser,
TABLE docai_demo.demo,
PROCESS_OPTIONS => (
JSON ‘{“layout_config”: {“chunking_config”: {“chunk_size”: 300}}}’)
);
Tạo vector embeddings cho chunks
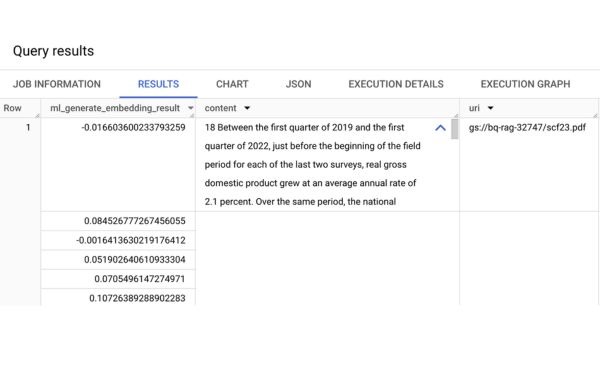
Để kích hoạt tìm kiếm và truy xuất ngữ nghĩa, Google sẽ tạo nhúng cho từng khối tài liệu bằng hàm ML.GENERATE_EMBEDDING và ghi chúng vào bảng BigQuery. Hàm này có hai đối trọng:
- Một mô hình điều khiển từ xa, là điểm cuối để nhúng Vertex AI
- Một cột từ bảng BigQuery chứa dữ liệu để nhúng
Tạo vector index trên embeddings
Để tìm kiếm hiệu quả qua các khối lớn dựa trên sự tương đồng về mặt ngữ nghĩa, chúng ta sẽ tạo vectơ index trên các nhúng. Nếu không cóvectơ index, việc thực hiện tìm kiếm đòi hỏi phải so sánh từng nhúng truy vấn với mọi nhúng trong tập dữ liệu của bạn, điều này tốn kém về mặt tính toán và gây chậm trễ khi xử lý một số lượng lớn các khối. Vectơ index sử dụng các kỹ thuật như tìm kiếm lân cận gần nhất để tăng tốc quá trình này
CREATE VECTOR INDEX my_index
ON docai_demo.embeddings(ml_generate_embedding_result)
OPTIONS(index_type = “TREE_AH”,
distance_type = “EUCLIDIAN”
);
Truy xuất các khối có liên quan và gửi đến LLM để tạo câu trả lời
Bây giờ chúng ta có thể thực hiện vector search để tìm các khối có ngữ nghĩa tương tự với truy vấn đầu vào của chúng ta. Trong trường hợp này, chúng ta hỏi giá trị tài sản ròng điển hình của gia đình đã thay đổi như thế nào trong ba năm mà báo cáo này đề cập.
SELECT
ml_generate_text_llm_result AS generated,
prompt
FROM
ML.GENERATE_TEXT( MODEL `docai_demo.gemini_flash`,
(
SELECT
CONCAT( ‘Did the typical family net worth change? How does this compare the SCF survey a decade earlier? Be concise and use the following context:’,
STRING_AGG(FORMAT(“context: %s and reference: %s”, base.content, base.uri), ‘,\n’)) AS prompt,
FROM
VECTOR_SEARCH( TABLE
`docai_demo.embeddings`,
‘ml_generate_embedding_result’,
(
SELECT
ml_generate_embedding_result,
content AS query
FROM
ML.GENERATE_EMBEDDING( MODEL `docai_demo.embedding_model`,
(
SELECT
‘Did the typical family net worth increase? How does this compare the SCF survey a decade earlier?’ AS content
)
)
),
top_k => 10,
OPTIONS => ‘{“fraction_lists_to_search”: 0.01}’)
),
STRUCT(512 AS max_output_tokens, TRUE AS flatten_json_output)
);
Các khối được lấy sau đó được gửi qua hàm ML.GENERATE_TEXT hàm này gọi điểm cuối của Gemini 1.5 Flash và tạo ra câu trả lời ngắn gọn cho câu hỏi của Google..
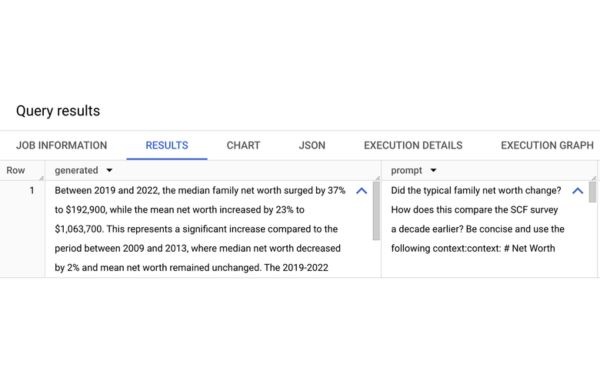
Và chúng ta có câu trả lời: giá trị tài sản ròng trung bình của gia đình tăng 37% từ năm 2019 đến năm 2022, đây là mức tăng đáng kể so với giai đoạn một thập kỷ trước đó, ghi nhận mức giảm 2%. Lưu ý rằng nếu bạn kiểm tra tài liệu gốc, thông tin này nằm trong văn bản, bảng và chú thích — theo truyền thống là những khu vực khó phân tích và suy ra kết quả!
Ví dụ này minh họa luồng RAG pipeline cơ bản, nhưng các ứng dụng thực tế thường yêu cầu cập nhật liên tục. Hãy tưởng tượng một trường hợp trong đó các báo cáo tài chính mới được thêm hàng ngày dựa trên lưu trữ đám mây. Để giữ cho Rag pipeline của bạn được cập nhật, hãy cân nhắc sử dụng BigQuery Workflows hoặc Cloud Composer để xử lý việc các tài liệu mới được thêm vào hàng giờ và tạo nhúng trong BigQuery. Các vectơ index sẽ được tự động làm mới khi dữ liệu cơ bản thay đổi, đảm bảo rằng bạn luôn truy vấn thông tin mới nhất.
Bắt đầu phân tích tài liệu trong BigQuery
Việc tích hợp Layout Parser của Document AI với BigQuery giúp các nhà phát triển dễ dàng xây dựng các Rag pipeline mạnh mẽ. Bằng cách tận dụng ML.PROCESS_DOCUMENT và các hàm học máy khác của BigQuery, bạn có thể hợp lý hóa quá trình xử lý trước tài liệu, tạo nhúng và thực hiện tìm kiếm ngữ nghĩa — tất cả đều trong BigQuery bằng SQL. Liên hệ Gimasys ngay hôm nay để khám phá thêm về giải pháp này!
Bài viết liên quan