Việc nhân sự phải liên tục “nhảy” qua lại giữa các nền tảng như Salesforce,…
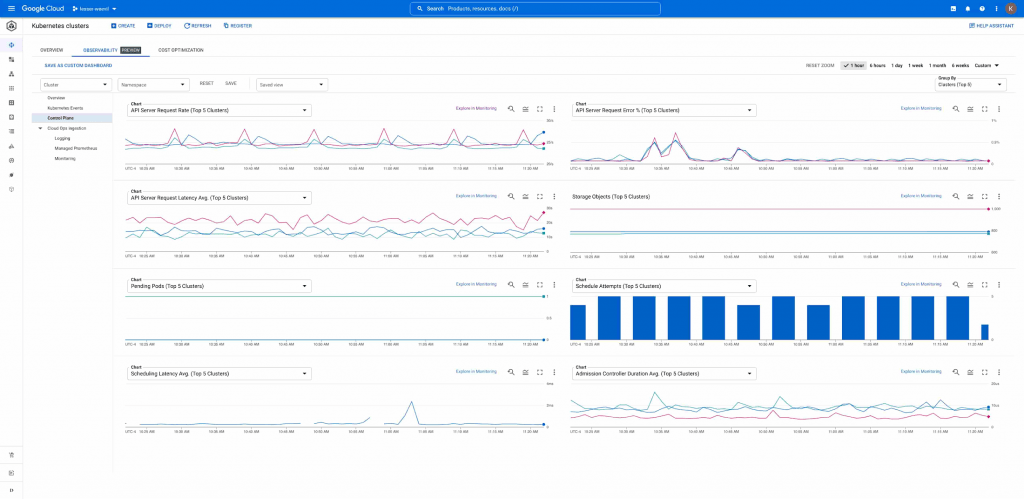
Các chỉ số Control Plane Kubernetes trong Google Kubernetes Engine (GKE)
Một khía cạnh thiết yếu của việc vận hành bất kỳ ứng dụng nào là khả năng quan sát tình trạng và hiệu suất của ứng dụng đó cũng như của cơ sở hạ tầng bên dưới để nhanh chóng giải quyết các vấn đề khi chúng phát sinh. Google Kubernetes Engine (GKE) đã cung cấp audit logs, operations logs và chỉ số cùng với dashboards có sẵn và báo cáo lỗi tự động để tạo điều kiện chạy các ứng dụng đáng tin cậy trên quy mô lớn. Sử dụng các nhật ký và chỉ số này, Hoạt động trên nền tảng đám mây cung cấp các cảnh báo, trang tổng quan giám sát và Trình khám phá nhật ký để nhanh chóng phát hiện, khắc phục sự cố và giải quyết các vấn đề.
Giới thiệu số liệu Control Plane Kubernetes và lý do chúng quan trọng
Ngoài các nguồn dữ liệu đo từ xa hiện có này, Google vui mừng thông báo rằng chúng tôi hiện đang công bố các số liệu Kubernetes control plane, hiện đã có sẵn. Với GKE, Google quản lý hoàn toàn Kubernetes control plane; tuy nhiên, khi khắc phục sự cố, có thể hữu ích nếu có quyền truy cập vào một số metric nhất định do Kubernetes control plane phát ra.
Là một phần trong tầm nhìn của Google nhằm làm cho Kubernetes dễ sử dụng và dễ vận hành hơn, các chỉ số Control plane này được tích hợp trực tiếp với Cloud Monitoring, vì vậy bạn không cần quản lý bất kỳ bộ sưu tập số liệu hoặc cấu hình thu thập dữ liệu nào.
Ví dụ: Để hiểu tình trạng của máy chủ API, bạn có thể sử dụng các số liệu như apiserver_request_total và apiserver_request_duration_seconds để theo dõi tải mà API Server đang trải qua, một phần nhỏ các yêu cầu API Server trả về lỗi và độ trễ phản hồi cho các yêu cầu nhận được bởi API Server. Ngoài ra, apiserver_storage_objects có thể rất hữu ích để theo dõi độ bão hòa của API Server, đặc biệt nếu bạn đang sử dụng custom controller. Chia nhỏ số liệu này theo nhãn tài nguyên để tìm ra tài nguyên hoặc Kubernetes custom controller nào có vấn đề.
Khi một Pod được tạo, ban đầu nó sẽ được đặt ở trạng thái “pending”, cho thấy nó chưa được lên lịch trên một Node. Trong một cluster lành mạnh, các Pod đang chờ xử lý được lên lịch tương đối nhanh chóng trên một Node, cung cấp cho khối lượng công việc các tài nguyên mà nó cần để chạy. Tuy nhiên, sự gia tăng liên tục về số lượng các Pod đang chờ xử lý có thể cho thấy sự cố khi Schedule các Pod đó, nguyên nhân có thể do không đủ resource hoặc cấu hình không phù hợp. Các chỉ số như Scheduler_pend_pods, Scheduler_schedule_attempts_total, Scheduler_preemption_attempts_total, Scheduler_preemption_victims và Scheduler_scheduling_attempt_duration_seconds có thể cảnh báo cho bạn về các vấn đề lập lịch tiềm ẩn, vì vậy bạn có thể nhanh chóng hành động để đảm bảo các nhóm của mình luôn sẵn sàng. Sử dụng kết hợp các chỉ số này sẽ giúp bạn hiểu rõ hơn về tình trạng của cụm của bạn. Ví dụ: nếu Scheduler_preemption_attempts_total tăng lên, điều đó có nghĩa là có các nhóm ưu tiên cao hơn có sẵn để được lên lịch và Schedule đang ưu tiên một số Pod đang chạy. Tuy nhiên, nếu giá trị của Scheduler_pend_pods cũng đang tăng lên, thì điều này có thể cho thấy rằng bạn không có đủ resource để phân bổ các pod có mức độ ưu tiên cao hơn.
Nếu Kubernetes schedule vẫn không thể tìm thấy một node phù hợp cho một pod, thì pod đó cuối cùng sẽ được đánh dấu là không thể schedule. Các chỉ số Kubernetes control plane cung cấp cho bạn khả năng hiển thị về các lỗi lập lịch pod và các pod không thể lập lịch. Tăng đột biến một trong hai nghĩa là Kubernetes schedule không thể tìm thấy một node thích hợp để chạy nhiều nhóm của bạn, điều này cuối cùng có thể làm giảm hiệu suất của ứng dụng của bạn. Trong nhiều trường hợp, tỷ lệ cao các pod không thể schedule sẽ không tự giải quyết cho đến khi bạn thực hiện một số hành động để giải quyết nguyên nhân cơ bản. Một nơi tốt đầu tiên để bắt đầu khắc phục sự cố là tìm kiếm các sự kiện Lập lịch trình không thành công gần đây. (Nếu bạn đã bật nhật ký hệ thống GKE, thì tất cả các sự kiện Kubernetes đều có sẵn trong Ghi nhật ký đám mây.) Các sự kiện Schedule không thành công này bao gồm một thông báo (ví dụ: “0/6 node khả dụng: 6 Không đủ cpu.”) Mô tả rất hữu ích chính xác lý do pod không thể được lên lịch trên bất kỳ node nào, cung cấp cho bạn hướng dẫn về cách giải quyết vấn đề.
Ví dụ cuối cùng: Nếu bạn thấy việc schedule công việc rất chậm, thì một nguyên nhân có thể là do webhook của bên thứ ba có thể đang tạo ra độ trễ đáng kể, khiến API server mất nhiều thời gian để schedule công việc. Các chỉ số Kubernetes control plane như apiserver_admission_webhook_admission_duration_seconds có thể hiển thị độ trễ webhook nhập học, giúp bạn xác định nguyên nhân gốc rễ của việc lên schedule công việc chậm và giảm thiểu sự cố.
Hiển thị
Không chỉ cung cấp các chỉ số Kubernetes control plane bổ sung này, Google còn vui mừng thông báo rằng tất cả các metric này đều được hiển thị trong phần Kubernetes Engine của Cloud Console, giúp dễ dàng xác định và điều tra các vấn đề trong- ngữ cảnh khi bạn đang quản lý các GKE cluster của mình.
Để xem các chỉ số control plane này, hãy chuyển đến phần cụm Kubernetes của Cloud Console, chọn tab “Observability” và chọn “Control plane”:
Vì tất cả các chỉ số Kubernetes Control plane đều được nhập vào Cloud Monitoring, bạn có thể tạo các chính sách cảnh báo trong Cloud Alerting để bạn được thông báo ngay khi có điều gì đó cần bạn chú ý.
PromQL compatible
Khi bạn bật chỉ số Kubernetes Control Plane cho các cụm GKE của mình, tất cả các chỉ số được thu thập bằng Google Cloud Managed Service for Prometheus. Điều này có nghĩa là các chỉ số được gửi đến Cloud Monitoring trong cùng một dự án GCP như cụm Kubernetes của bạn và có thể được truy vấn bằng PromQL thông qua API giám sát đám mây và trình khám phá số liệu.
Ví dụ: Bạn có thể theo dõi bất kỳ mức tăng đột biến nào về độ trễ phản hồi của máy chủ API phân vị thứ 99 bằng cách sử dụng truy vấn PromQL này:
sum by (instance, verb) (histogram_quantile (0,99, rate (apiserver_request_duration_seconds_bucket {cluster = “cluster-name”} [5m])) )
Hỗ trợ của bên thứ ba
Nếu bạn giám sát cụm GKE của mình bằng các công cụ khả năng quan sát phổ biến của bên thứ ba, thì bất kỳ công cụ quan sát nào của bên thứ ba đều có thể nhập các chỉ số mặt phẳng điều khiển Kubernetes này bằng cách sử dụng API giám sát đám mây.
Ví dụ: Nếu bạn là khách hàng của Datadog và bạn đã bật số liệu mặt phẳng điều khiển Kubernetes cho cụm GKE của mình, thì Datadog cung cấp hình ảnh trực quan nâng cao bao gồm các số liệu Kubernetes Control plane từ API server, schedule và controller manager.
Giá cả
Tất cả các chỉ số của Kubernetes Control Plane được tính theo giá chuẩn cho các chỉ số được nhập từ Google Cloud Managed Service for Prometheus.
Nếu doanh nghiệp của bạn đang quan tâm tới nền tảng Google Cloud thì có thể kết nối với Gimasys – đối tác cấp cao của Google tại Việt Nam để được tư vấn giải pháp xây dựng ứng dụng theo nhu cầu riêng của doanh nghiệp nhé. Liên hệ ngay:
- Gimasys – Google Cloud Premier Partner
- Hotline: Hà Nội: 0987 682 505 – Hồ Chí Minh: 0974 417 099
- Email: gcp@gimasys.com
Nguồn: Gimasys
Bài viết liên quan