Ngày 02/04 vừa qua, hội thảo trực tuyến do Gimasys phối hợp cùng Google Cloud…
Cách Google đáp ứng hiệu suất chuẩn SSD nhưng giá ở mức HDD với sức mạnh Colossus
Từ YouTube và Gmail đến BigQuery và Cloud Storage, gần như tất cả các sản phẩm của Google đều phụ thuộc vào Colossus – một hệ thống lưu trữ phân tán nền tảng hàng đầu. Là nền tảng lưu trữ chung của Google, Colossus đạt được thông lượng ngang bằng hoặc vượt trội so với các hệ thống tệp song song tốt nhất, có khả năng quản lý và mở rộng như một hệ thống lưu trữ đối tượng, đồng thời cung cấp mô hình lập trình dễ sử dụng cho tất cả các nhóm tại Google. Hơn thế nữa, nó làm được tất cả những điều này trong khi phục vụ các sản phẩm có yêu cầu vô cùng đa dạng, từ quy mô, chi phí, thông lượng đến độ trễ.
| Ứng dụng | Kích thước I/O | Hiệu suất mong đợi |
| BigQuery quét dữ liệu | Hàng trăm KB đến hàng chục MB | TB/s |
| Cloud Storage – standard class | KB đến hàng chục MB | Hàng trăm mili-giây |
| Tin nhắn Gmail | Dưới hàng trăm KB | Hàng chục mili-giây |
| Tệp đính kèm Gmail | KB đến MB | Vài giây |
| Hyperdisk đọc dữ liệu | KB đến hàng trăm KB | <1 mili-giây |
| Lưu trữ video YouTube | MB | Vài giây |
Sự linh hoạt của Colossus xuất hiện trong một số sản phẩm Google Cloud có sẵn công khai. Hyperdisk ML sử dụng SSD của Colossus để hỗ trợ 2.500 node đọc với tốc độ 1,2 TB/s — một khả năng mở rộng ấn tượng. Spanner sử dụng Colossus để kết hợp lưu trữ HDD giá rẻ với lưu trữ SSD siêu nhanh trong cùng một hệ thống tệp, tạo nền tảng cho tính năng lưu trữ phân tầng. Cloud Storage sử dụng bộ nhớ đệm SSD của Colossus để cung cấp khả năng lưu trữ rẻ nhất trong khi vẫn hỗ trợ I/O chuyên sâu cho các ứng dụng AI/ML đòi hỏi cao. Cuối cùng, lưu trữ dựa trên Colossus của BigQuery cung cấp I/O siêu nhanh cho các truy vấn cực lớn.
Trước đây, Gimasys đã viết về Colossus và muốn cung cấp cho bạn cái nhìn sâu hơn về cách các khả năng của nó hỗ trợ hoạt động kinh doanh đang thay đổi của Google Cloud, cũng như các tính năng mới mà Google đã thêm vào, đặc biệt là hỗ trợ SSD.
Tổng quan về Colossus
Nhưng trước tiên, đây là một số thông tin cơ bản về Colossus:
- Colossus là sự phát triển từ Google File System (GFS).
- Hệ thống tệp Colossus truyền thống nằm trong một trung tâm dữ liệu duy nhất.
- Colossus đơn giản hóa mô hình lập trình của GFS thành một hệ thống lưu trữ chỉ ghi nối tiếp (append-only), kết hợp giao diện lập trình quen thuộc của hệ thống tệp với khả năng mở rộng của lưu trữ đối tượng.
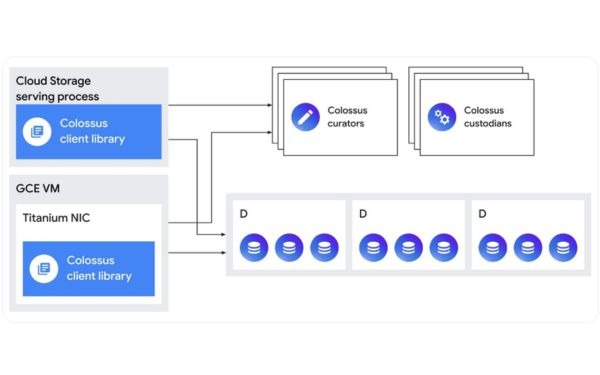
- Dịch vụ siêu dữ liệu của Colossus bao gồm:
- “Curators”: Xử lý các thao tác điều khiển tương tác như tạo và xóa tệp.
- “Custodians”: Duy trì độ bền và tính sẵn sàng của dữ liệu cũng như cân bằng dung lượng ổ đĩa.
- Máy khách Colossus tương tác với curators để lấy siêu dữ liệu, sau đó trực tiếp lưu dữ liệu lên “D servers”, nơi lưu trữ HDD hoặc SSD.
Colossus cũng là một sản phẩm theo vùng (zonal). Google đã xây dựng một hệ thống tệp Colossus duy nhất cho mỗi cụm, một khối xây dựng nội bộ của một vùng Google Cloud. Hầu hết các trung tâm dữ liệu có một cụm và do đó có một hệ thống tệp Colossus, bất kể có bao nhiêu khối lượng công việc chạy bên trong cụm đó. Nhiều hệ thống tệp Colossus có dung lượng lưu trữ lên đến nhiều exabyte, bao gồm hai hệ thống tệp khác nhau có dung lượng vượt quá 10 exabyte mỗi hệ thống. Khả năng mở rộng cao như vậy giúp đảm bảo rằng ngay cả những ứng dụng đòi hỏi khắt khe nhất cũng không bị thiếu dung lượng đĩa gần tài nguyên tính toán của cụm trong một vùng.
Những ứng dụng yêu cầu cao này cũng cần một lượng lớn IOPS và thông lượng. Trên thực tế, một số hệ thống tệp lớn nhất của Google thường xuyên vượt quá thông lượng đọc 50 TB/s và thông lượng ghi 25 TB/s. Đây là đủ thông lượng để truyền hơn 100 bộ phim 8K đầy đủ mỗi giây!
Google cũng không chỉ dựa vào Colossus để hỗ trợ các I/O phát trực tuyến lớn. Nhiều ứng dụng thực hiện các thao tác ghi nhật ký nhỏ hoặc đọc ngẫu nhiên nhỏ. Cụm bận rộn nhất của họ cung cấp hơn 600 triệu IOPS, bao gồm cả đọc và ghi.
Tất nhiên, để đạt được hiệu suất cao như vậy, bạn cần đưa dữ liệu đến đúng vị trí. Rất khó để đọc ở tốc độ 50 TB/s nếu tất cả dữ liệu của bạn nằm trên các ổ đĩa chậm. Điều này dẫn đến hai cải tiến quan trọng mới trong Colossus: bộ nhớ đệm SSD và định vị dữ liệu SSD, cả hai đều được hỗ trợ bởi một hệ thống mà Google gọi là “L4”.
Có gì mới trong việc định vị SSD của Colossus?
Trong bài viết blog trước đây về Colossus, Google đã đề cập đến cách họ đặt dữ liệu “nóng” nhất trên SSD và cân bằng phần dữ liệu còn lại trên tất cả các thiết bị trong cụm. Điều này càng trở nên quan trọng hơn ngày nay, khi SSD ngày càng trở nên hợp lý hơn về chi phí, gia tăng vai trò của chúng trong các trung tâm dữ liệu của Google. Giờ đây, không có nhà thiết kế lưu trữ nào chỉ xây dựng một hệ thống hoàn toàn bằng HDD nữa.
Tuy nhiên, lưu trữ chỉ bằng SSD vẫn có chi phí cao hơn đáng kể so với một hệ thống lưu trữ kết hợp giữa SSD và HDD. Thách thức đặt ra là làm sao để đặt đúng dữ liệu — dữ liệu có số lần truy cập I/O nhiều nhất hoặc yêu cầu độ trễ thấp nhất — lên SSD, trong khi vẫn giữ phần lớn dữ liệu trên HDD.
Vậy, Colossus xác định dữ liệu phù hợp nhất như thế nào?
Colossus có một số cách để chọn dữ liệu phù hợp để đặt trên SSD:
- Buộc hệ thống đặt dữ liệu lên SSD: Ở đây, một người dùng nội bộ của Colossus có thể ép hệ thống lưu dữ liệu lên SSD bằng cách sử dụng đường dẫn:
/cns/ex/home/leg/partition=ssd/myfile.
Đây là cách đơn giản nhất và đảm bảo rằng toàn bộ tệp được lưu trữ trên SSD. Tuy nhiên, đây cũng là lựa chọn tốn kém nhất. - Sử dụng phương pháp định vị lai (hybrid placement): Những người dùng có kinh nghiệm hơn có thể tận dụng “định vị lai” và yêu cầu hệ thống Colossus chỉ đặt một bản sao trên SSD bằng đường dẫn:
/cns/ex/home/leg/partition=ssd.1/myfile.
Đây là một phương pháp tiết kiệm chi phí hơn, nhưng nếu máy chủ D có bản sao SSD không khả dụng, việc truy cập dữ liệu sẽ bị ảnh hưởng bởi độ trễ của HDD.
- Sử dụng L4: Đối với phần lớn dữ liệu tại Google, hầu hết các nhà phát triển sử dụng công nghệ bộ nhớ đệm SSD phân tán L4, giúp tự động chọn dữ liệu phù hợp nhất để đặt trên SSD.
Bộ nhớ đệm đọc L4
Bộ nhớ đệm SSD phân tán L4 phân tích mô hình truy cập của ứng dụng và tự động đặt dữ liệu phù hợp nhất trên SSD. Khi hoạt động như một bộ nhớ đệm đọc, các máy chủ chỉ mục L4 duy trì một bộ nhớ đệm đọc phân tán:
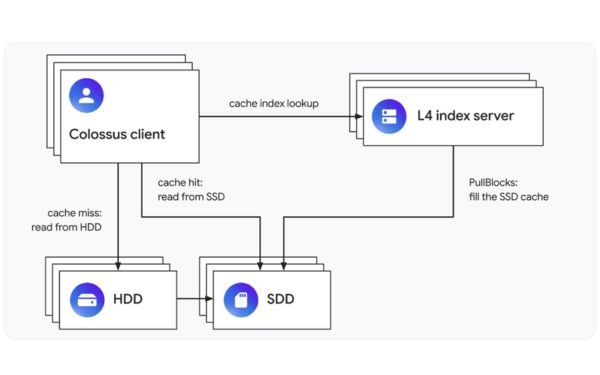
Điều đó có nghĩa là khi một ứng dụng muốn đọc dữ liệu, trước tiên nó sẽ kiểm tra với một máy chủ chỉ mục L4. Máy chủ chỉ mục này sẽ thông báo cho ứng dụng biết liệu dữ liệu có trong bộ nhớ đệm hay không. Nếu có, ứng dụng sẽ đọc dữ liệu từ một hoặc nhiều SSD. Nếu không, bộ nhớ đệm sẽ thông báo rằng đây là một lần bỏ lỡ bộ nhớ đệm (cache miss), và ứng dụng sẽ lấy dữ liệu từ ổ đĩa mà Colossus đã đặt nó.
Khi xảy ra cache miss, L4 có thể quyết định chèn dữ liệu được truy cập vào bộ nhớ đệm SSD. Nó làm điều này bằng cách yêu cầu một máy chủ lưu trữ SSD chuyển dữ liệu từ máy chủ HDD. Khi bộ nhớ đệm đầy, L4 sẽ xóa một số mục khỏi bộ nhớ đệm để giải phóng không gian cho dữ liệu mới.
L4 có thể điều chỉnh mức độ “tích cực” trong việc đặt dữ liệu lên SSD. Google sử dụng một thuật toán dựa trên Machine Learning (ML) để quyết định chính sách phù hợp cho từng khối lượng công việc: đưa dữ liệu vào bộ nhớ đệm L4 ngay khi nó được ghi, sau lần đọc đầu tiên, hoặc chỉ sau lần đọc thứ hai trong một khoảng thời gian ngắn.
Cách tiếp cận này hoạt động tốt đối với các ứng dụng thường xuyên đọc cùng một dữ liệu, giúp cải thiện đáng kể hiệu suất IOPS và băng thông. Tuy nhiên, nó có một điểm yếu lớn: Google vẫn ghi dữ liệu mới vào HDD. Trên thực tế, có những loại dữ liệu quan trọng khác mà bộ nhớ đệm đọc L4 không giúp tiết kiệm tài nguyên nhiều như mong muốn, cụ thể là dữ liệu được ghi, đọc và xóa nhanh chóng (chẳng hạn như kết quả trung gian cho một tác vụ xử lý hàng loạt lớn), và nhật ký giao dịch cơ sở dữ liệu và các tệp khác có nhiều phần bổ sung nhỏ. Cả hai loại khối lượng công việc này đều không phù hợp với HDD, vì vậy tốt hơn hết là ghi trực tiếp chúng vào SSD và bỏ qua HDD hoàn toàn.
L4 writeback cho Colossus
Bây giờ, hãy tưởng tượng rằng một người dùng nội bộ của Colossus muốn đặt một phần dữ liệu của họ lên SSD. Họ cần suy nghĩ cẩn thận về tệp nào nên lưu trên SSD và cần mua bao nhiêu dung lượng SSD cho khối lượng công việc của họ. Nếu họ có các tệp cũ không còn được truy cập, họ có thể muốn di chuyển dữ liệu đó từ SSD sang HDD. Nhưng từ kinh nghiệm quan sát người dùng, Google biết rằng quyết định các thông số này rất khó khăn. Để hỗ trợ người dùng, Google cũng đã cải tiến dịch vụ L4 để tự động hóa công việc này.
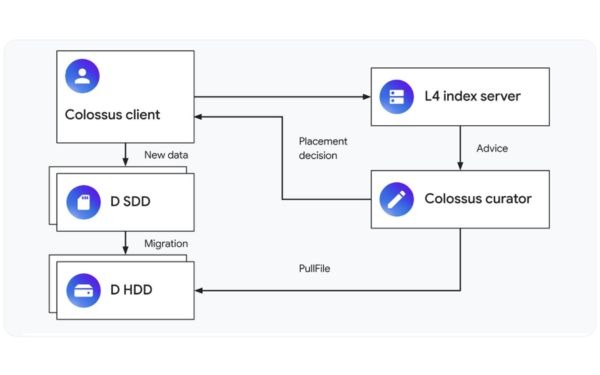 Khi được sử dụng như một bộ nhớ đệm ghi lại (writeback cache), dịch vụ L4 sẽ tư vấn cho các quản trị viên Colossus về việc có nên đặt một tệp mới trên SSD hay không và trong bao lâu. Đây là một vấn đề phức tạp! Khi tệp được tạo, Colossus chỉ biết ứng dụng đang tạo tệp và tên của tệp — nó không thể biết chắc chắn tệp đó sẽ được sử dụng như thế nào.
Khi được sử dụng như một bộ nhớ đệm ghi lại (writeback cache), dịch vụ L4 sẽ tư vấn cho các quản trị viên Colossus về việc có nên đặt một tệp mới trên SSD hay không và trong bao lâu. Đây là một vấn đề phức tạp! Khi tệp được tạo, Colossus chỉ biết ứng dụng đang tạo tệp và tên của tệp — nó không thể biết chắc chắn tệp đó sẽ được sử dụng như thế nào.
Để giải quyết vấn đề này, Google sử dụng cùng một phương pháp như bộ nhớ đệm đọc L4 được mô tả trong bài báo CacheSack đã đề cập trước đó. Ứng dụng sẽ cung cấp cho L4 các đặc điểm như loại tệp hoặc siêu dữ liệu về cột cơ sở dữ liệu chứa dữ liệu. L4 sử dụng các đặc điểm này để phân loại tệp thành các “nhóm” và quan sát các mẫu I/O của từng nhóm theo thời gian. Những mẫu I/O này sẽ được sử dụng để chạy mô phỏng trực tuyến với các chính sách lưu trữ khác nhau, chẳng hạn như “lưu trên SSD trong một giờ,” “lưu trên SSD trong hai giờ,” hoặc “không lưu trên SSD.” Dựa trên kết quả mô phỏng, L4 sẽ chọn chính sách tối ưu nhất cho từng nhóm dữ liệu.
Những mô phỏng trực tuyến này cũng có một mục đích quan trọng khác: chúng dự đoán cách L4 sẽ phân bổ dữ liệu nếu có nhiều hoặc ít dung lượng SSD hơn. Nhờ đó, Google có thể tính toán lượng I/O có thể giảm tải từ HDD sang SSD với các mức dung lượng SSD khác nhau. Những thông tin này sẽ giúp định hướng việc mua phần cứng SSD mới và hỗ trợ các nhà hoạch định trong việc điều chỉnh dung lượng SSD giữa các ứng dụng để tối ưu hóa hiệu suất.
Khi có chỉ thị, quản trị viên Colossus có thể hướng dẫn hệ thống lưu các tệp mới trên SSD thay vì HDD mặc định. Sau một khoảng thời gian nhất định, nếu tệp vẫn tồn tại, quản trị viên sẽ chuyển dữ liệu từ SSD sang HDD.
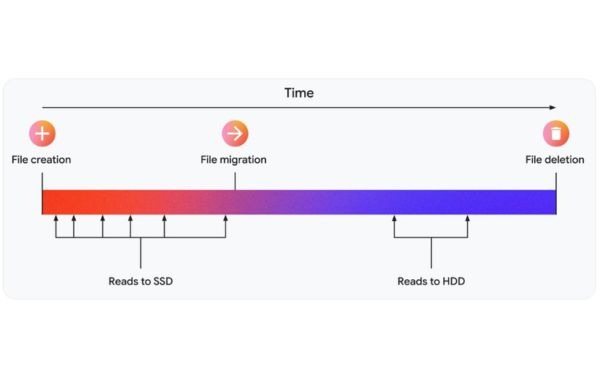 Khi hệ thống mô phỏng của L4 dự đoán chính xác các mô hình truy cập tệp, Google chỉ đặt một phần nhỏ dữ liệu lên SSD. Những SSD này sẽ hấp thụ phần lớn các lượt đọc (thường xảy ra với các tệp mới được tạo) trước khi dữ liệu được di chuyển sang bộ nhớ rẻ hơn, giúp giảm thiểu tổng chi phí.
Khi hệ thống mô phỏng của L4 dự đoán chính xác các mô hình truy cập tệp, Google chỉ đặt một phần nhỏ dữ liệu lên SSD. Những SSD này sẽ hấp thụ phần lớn các lượt đọc (thường xảy ra với các tệp mới được tạo) trước khi dữ liệu được di chuyển sang bộ nhớ rẻ hơn, giúp giảm thiểu tổng chi phí.
Trong kịch bản lý tưởng nhất, tệp sẽ bị xóa trước khi Google di chuyển nó sang HDD, qua đó tránh hoàn toàn các hoạt động I/O trên HDD.
Kết luận
Tóm lại, Colossus, kết hợp cùng sức mạnh hạ tầng của Google Cloud, đã hiện thực hóa một giải pháp lưu trữ đột phá, mang đến hiệu suất SSD vượt trội với chi phí tương đương ổ cứng HDD truyền thống. Điều này mở ra cơ hội to lớn cho các doanh nghiệp, đặc biệt là những đơn vị xử lý lượng lớn dữ liệu và đòi hỏi tốc độ truy cập nhanh chóng, để tối ưu hóa chi phí lưu trữ mà không phải hy sinh hiệu suất. Sự đổi mới này không chỉ nâng cao hiệu quả hoạt động mà còn thúc đẩy quá trình chuyển đổi số mạnh mẽ trong nhiều lĩnh vực.
Bài viết liên quan