
Điện toán đám mây (Cloud Computing) đã trở thành vấn đề cốt lõi cho hạ…
Giới thiệu Firehose: công cụ mã nguồn mở của Gojek để nhập dữ liệu liền mạch vào BigQuery và Cloud Storage
Là công ty hyperlocal lớn nhất Indonesia, Gojek đã phát triển từ một dịch vụ gọi xe mô tô thành một nền tảng di động theo yêu cầu, cung cấp một loạt các dịch vụ bao gồm vận chuyển, hậu cần, giao thực phẩm và thanh toán. Tổng cộng có 2 triệu đối tác tài xế đảm nhận quãng đường trung bình là 16,5 triệu km mỗi ngày, trở thành đối tác vận tải thực tế của Gojek Indonesia.
Để tiếp tục hỗ trợ sự phát triển này, Gojek điều hành hàng trăm dịch vụ vi mô giao tiếp qua nhiều trung tâm dữ liệu. Các ứng dụng dựa trên kiến trúc hướng sự kiện và tạo ra hàng tỷ sự kiện mỗi ngày. Để trao quyền cho việc ra quyết định dựa trên dữ liệu, Gojek sử dụng các sự kiện này trên các sản phẩm và dịch vụ để phân tích, học máy, v.v.
Các thách thức khi nhập kho dữ liệu
Để hiểu được lượng lớn dữ liệu – và để hiểu rõ hơn về khách hàng cho mục đích phát triển ứng dụng, hỗ trợ khách hàng, tăng trưởng và mục đích tiếp thị – dữ liệu trước tiên phải được nhập vào kho dữ liệu. Gojek sử dụng BigQuery làm kho dữ liệu chính. Nhưng việc nhập các sự kiện ở quy mô của Gojek, với những thay đổi nhanh chóng, đặt ra những thách thức sau:
- Với nhiều sản phẩm và microservices được cung cấp, Gojek phát hành các chủ đề Kafka mới hầu như mỗi ngày và chúng cần được nhập cho mục đích phân tích. Điều này có thể nhanh chóng dẫn đến chi phí hoạt động đáng kể cho nhóm kỹ thuật dữ liệu đang triển khai các công việc mới để tải dữ liệu vào BigQuery và Cloud Storage.
- Các thay đổi schema thường xuyên trong các chủ đề của Kafka yêu cầu người tiêu dùng của các chủ đề đó tải schema mới để tránh mất dữ liệu và nắm bắt các thay đổi gần đây hơn.
- Khối lượng dữ liệu có thể thay đổi và phát triển theo cấp số nhân khi mọi người bắt đầu xây dựng sản phẩm mới và ghi lại các hoạt động mới về chủ đề mới. Mỗi chủ đề cũng có thể có tải khác nhau trong giờ làm việc cao điểm. Khách hàng cần xử lý khối lượng dữ liệu ngày càng tăng để nhanh chóng mở rộng quy mô theo nhu cầu kinh doanh của họ.
Để giải quyết những thách thức này, Gojek sử dụng Firehose, một dịch vụ đám mây gốc để cung cấp dữ liệu phát trực tuyến theo thời gian thực đến các điểm đến như service endpoints, cơ sở dữ liệu được quản lý, data lakes và kho dữ liệu như Cloud Storage và BigQuery. Firehose là một phần của Open Data Ops Foundation (ODPF) và hoàn toàn là mã nguồn mở. Gojek là một trong những người đóng góp chính cho ODPF.
Dưới đây là các tính năng chính của Firehose:
- Sinks – Firehose hỗ trợ truyền dữ liệu xuống log console, HTTP, GRPC, PostgresDB (JDBC), InfluxDB, Elastic Search, Redis, Prometheus, MongoDB, GCS và BigQuery.
- Khả năng mở rộng – Firehose cho phép người dùng thêm sink tùy chỉnh với giao diện được xác định rõ ràng hoặc chọn từ các sink hiện có.
- Quy mô – Firehose mở rộng quy mô ngay lập tức, theo cả chiều dọc và chiều ngang, để mang lại hiệu suất cao cho hệ thống phát trực tuyến mà không bị giảm dữ liệu.
- Thời gian chạy – Firehose có thể chạy bên trong các containers hoặc máy ảo trong môi trường thời gian chạy được quản lý hoàn toàn như Kubernetes.
- Chỉ số – Firehose luôn cho bạn biết điều gì đang xảy ra với việc triển khai của mình, với tính năng giám sát thông lượng, thời gian phản hồi, lỗi được tích hợp sẵn và hơn thế nữa.
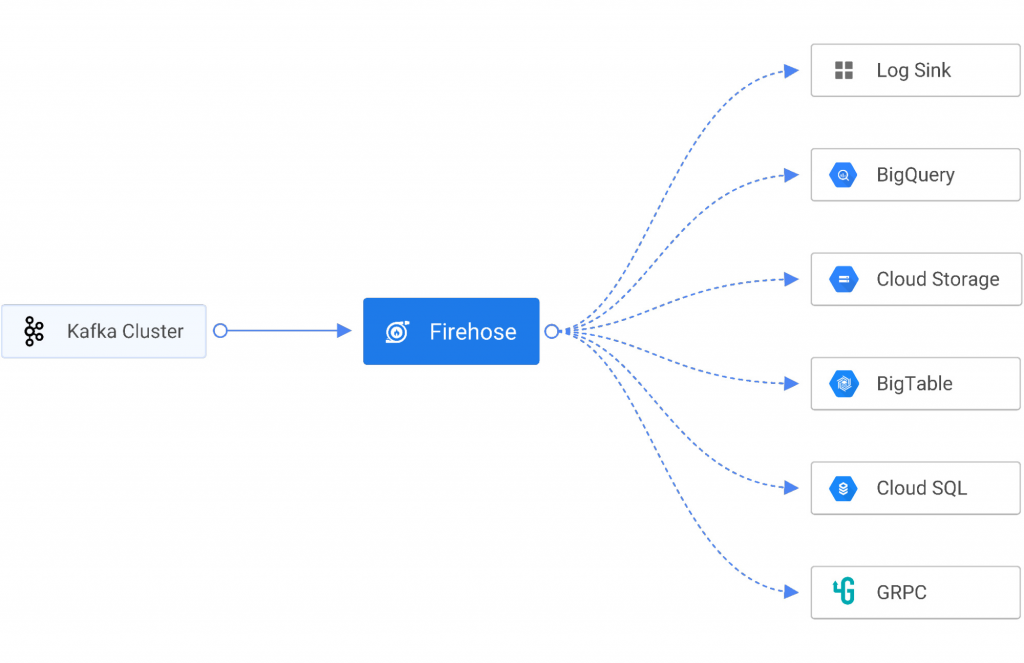
Các ưu điểm chính
Sử dụng Firehose để nhập dữ liệu trong BigQuery và Cloud Storage có nhiều ưu điểm.
Độ tin cậy
Firehose được thử nghiệm thực chiến để nhập dữ liệu quy mô lớn. Tại Gojek, Firehose phát trực tuyến 600 chủ đề Kafka trong BigQuery và 700 chủ đề Kafka trong Cloud Storage. Trung bình, 6 tỷ sự kiện được nhập hàng ngày trong BigQuery, dẫn đến hơn 10 terabyte dữ liệu nhập hàng ngày.
Nhập trực tuyến
Một chủ đề Kafka có thể tạo ra tới hàng tỷ bản ghi trong một ngày. Tùy thuộc vào bản chất của doanh nghiệp, khả năng mở rộng và làm mới dữ liệu là chìa khóa để đảm bảo khả năng sử dụng của dữ liệu đó, bất kể tải. Firehose sử dụng quá trình nhập phát trực tuyến BigQuery để tải dữ liệu trong thời gian gần thực. Điều này cho phép các nhà phân tích truy vấn dữ liệu trong vòng năm phút kể từ khi nó được tạo ra.
Sự phát triển của schema
Với nhiều sản phẩm và microservice được cung cấp, các chủ đề Kafka mới được phát hành hầu như mỗi ngày và schema của các chủ đề Kafka liên tục phát triển khi dữ liệu mới được tạo ra. Một thách thức chung là đảm bảo rằng khi các chủ đề này phát triển, các thay đổi về schema của chúng sẽ được điều chỉnh trong bảng BigQuery và Cloud Storage. Firehose theo dõi các thay đổi của schema bằng cách tích hợp với Stencil, một cơ quan đăng ký schema gốc đám mây và tự động cập nhật schema của các bảng BigQuery mà không cần sự can thiệp của con người. Điều này làm giảm lỗi dữ liệu và tiết kiệm cho các nhà phát triển hàng trăm giờ.
Cơ sở hạ tầng đàn hồi
Firehose có thể được triển khai trên Kubernetes và chạy như một dịch vụ không trạng thái. Điều này cho phép Firehose mở rộng quy mô theo chiều ngang khi khối lượng dữ liệu thay đổi.
Tổ chức dữ liệu trong lưu trữ đám mây
Firehose GCS Sink cung cấp khả năng lưu trữ dữ liệu dựa trên thông tin mốc thời gian cụ thể, cho phép người dùng tùy chỉnh cách phân vùng dữ liệu của họ trong Cloud Storage.
Hỗ trợ nhiều loại phần mềm nguồn mở
Được xây dựng để mang lại tính linh hoạt và độ tin cậy, các sản phẩm Google Cloud như BigQuery và Cloud Storage được tạo ra để hỗ trợ kiến trúc đa đám mây. Phần mềm mã nguồn mở như Firehose chỉ là một trong nhiều ví dụ có thể giúp các nhà phát triển và kỹ sư tối ưu hóa năng suất. Kết hợp với nhau, các công cụ này có thể cung cấp một quy trình nhập dữ liệu liền mạch, ít bảo trì hơn và tự động hóa tốt hơn.
Nếu doanh nghiệp của bạn đang quan tâm tới nền tảng Google Cloud Platform thì có thể kết nối với Gimasys – đối tác cấp cao của Google tại Việt Nam để được tư vấn giải pháp xây dựng ứng dụng theo nhu cầu riêng của doanh nghiệp nhé. Liên hệ ngay:
- Gimasys – Google Cloud Premier Partner
- Hotline: Hà Nội: 0987 682 505 – Hồ Chí Minh: 0974 417 099
- Email: gcp@gimasys.com
Nguồn: Gimasys
Bài viết liên quan


