
Trong quá trình vận hành, các chuỗi hoạt động như họp trực tuyến, đào tạo…
Phân tích dữ liệu, lựa chọn tính năng cho các mô hình ML tốt hơn
Khi bạn bắt đầu với một dự án máy học (ML), một nguyên tắc quan trọng cần ghi nhớ là dữ liệu là tất cả. Người ta thường nói rằng nếu ML là động cơ tên lửa, thì nhiên liệu là dữ liệu (chất lượng cao) được cung cấp cho thuật toán ML. Tuy nhiên, tìm ra sự thật và cái nhìn sâu sắc từ một đống dữ liệu có thể là một công việc phức tạp và dễ bị lỗi. Để có một khởi đầu vững chắc cho dự án ML của bạn, việc phân tích dữ liệu trước là hết sức quan trọng, một trong các bước là mô tả dữ liệu bằng các kỹ thuật thống kê và trực quan hóa để đưa các khía cạnh quan trọng của dữ liệu đó vào trọng tâm để phân tích thêm. Trong quá trình đó, điều quan trọng là bạn phải hiểu thật kĩ về:
- Các thuộc tính của dữ liệu: như các thuộc tính lược đồ và thống kê;
- Chất lượng của dữ liệu: như các giá trị bị thiếu và các loại dữ liệu không nhất quán;
- Sức mạnh dự đoán của dữ liệu: chẳng hạn như mối quan hệ của các tính năng với mục tiêu.
Quá trình này là nền tảng cho các bước lựa chọn tính năng và kỹ thuật tiếp theo, và nó cung cấp một nền tảng vững chắc để xây dựng các mô hình ML tốt hơn.
Có nhiều cách tiếp cận khác nhau để tiến hành phân tích dữ liệu thăm dò (EDA) ngoài kia, vì vậy thật khó để biết phân tích nào cần thực hiện và làm thế nào để thực hiện đúng. Để củng cố các khuyến nghị về việc tiến hành EDA, làm sạch dữ liệu và lựa chọn tính năng phù hợp trong các dự án ML, Google sẽ tóm tắt và cung cấp hướng dẫn ngắn gọn từ cả hai quan điểm trực quan (trực quan) và nghiêm ngặt (thống kê). Dựa trên kết quả phân tích, sau đó bạn có thể xác định lựa chọn tính năng và đề xuất kỹ thuật tương ứng. Bạn cũng có thể xem thêm hướng dẫn theo link này.
Bạn cũng có thể kiểm tra Công cụ đề xuất tính năng và khám phá dữ liệu tự động mà Google đã phát triển để giúp bạn tự động hóa phân tích được đề xuất, bất kể quy mô của dữ liệu, sau đó tạo báo cáo được tổ chức tốt để trình bày kết quả.
EDA, lựa chọn tính năng và kỹ thuật tính năng thường được gắn với nhau và là những bước quan trọng trong hành trình ML. Với sự phức tạp của dữ liệu và các vấn đề kinh doanh tồn tại ngày nay (như chấm điểm tín dụng trong tài chính và dự báo nhu cầu trong bán lẻ), làm thế nào kết quả của EDA thích hợp có thể ảnh hưởng đến các quyết định tiếp theo của bạn là một câu hỏi lớn. Trong bài đăng này, Google sẽ hướng dẫn bạn một số quyết định mà bạn sẽ đưa ra về dữ liệu của mình cho một dự án cụ thể và chọn loại phân tích nào sẽ sử dụng, cùng với trực quan hóa, công cụ và xử lý tính năng.
Hãy bắt đầu khám phá các loại phân tích mà bạn có thể chọn.
Phân tích dữ liệu thống kê
Với kiểu phân tích này, việc thăm dò dữ liệu có thể được tiến hành từ ba góc độ khác nhau: mô tả, tương quan và theo ngữ cảnh. Mỗi loại giới thiệu thông tin bổ sung về các thuộc tính và khả năng dự đoán của dữ liệu, giúp bạn đưa ra quyết định sáng suốt dựa trên kết quả phân tích.
1. Phân tích mô tả (Phân tích đơn biến)
Phân tích mô tả, hoặc phân tích đơn biến, cung cấp sự hiểu biết về các đặc tính của từng thuộc tính của bộ dữ liệu. Nó cũng cung cấp bằng chứng quan trọng cho quá trình tiền xử lý và lựa chọn trong giai đoạn sau. Bảng sau liệt kê phân tích được đề xuất cho các thuộc tính phổ biến, số, phân loại và văn bản.
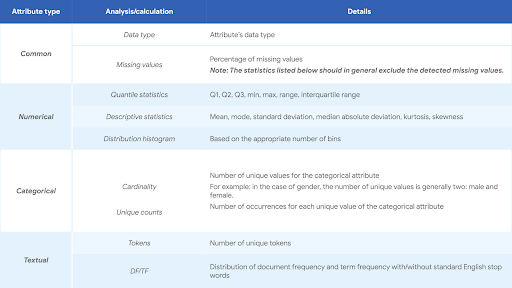
2. Phân tích tương quan (phân tích bivariate)
Phân tích tương quan (hoặc phân tích bivariate) kiểm tra mối quan hệ giữa hai thuộc tính, giả sử X và Y và kiểm tra xem X và Y có tương quan hay không. Phân tích này có thể được thực hiện từ hai quan điểm để có được sự kết hợp khác nhau có thể:
- Phân tích định tính. Điều này thực hiện tính toán các thống kê mô tả của các thuộc tính số / phân loại phụ thuộc theo từng giá trị duy nhất của thuộc tính phân loại độc lập. Phối cảnh này giúp hiểu trực giác mối quan hệ giữa X và Y. Trực quan hóa thường được sử dụng cùng với phân tích định tính như một cách trực quan hơn để trình bày kết quả.

- Phân tích định lượng. Đây là một bài kiểm tra định lượng về mối quan hệ giữa X và Y, dựa trên khung kiểm tra giả thuyết. Viễn cảnh này cung cấp một phương pháp chính thức và toán học để xác định một cách định lượng sự tồn tại và / hoặc sức mạnh của mối quan hệ.

3. Phân tích bối cảnh
Phân tích mô tả và phân tích tương quan đều đủ chung để được thực hiện trên bất kỳ tập dữ liệu có cấu trúc nào, cả hai đều không yêu cầu thông tin ngữ cảnh. Để hiểu thêm hoặc lập hồ sơ cho tập dữ liệu đã cho và để hiểu thêm về tên miền cụ thể, bạn có thể sử dụng một trong hai phân tích dựa trên thông tin theo ngữ cảnh phổ biến:
- Phân tích dựa trên thời gian:Trong nhiều bộ dữ liệu trong thế giới thực, dấu thời gian (hoặc thuộc tính liên quan đến thời gian tương tự) là một trong những phần chính của thông tin theo ngữ cảnh. Quan sát và / hoặc hiểu các đặc điểm của dữ liệu theo chiều thời gian, với các mức độ chi tiết khác nhau, là điều cần thiết để hiểu quy trình tạo dữ liệu và đảm bảo chất lượng dữ liệu
- Phân tích dựa trên tác nhân: Thay thế cho thời gian, thuộc tính phổ biến khác là nhận dạng duy nhất (ID, chẳng hạn như ID người dùng) của mỗi bản ghi. Phân tích tập dữ liệu bằng cách tổng hợp dọc theo kích thước tác nhân, tức là, biểu đồ số lượng hồ sơ trên mỗi tác nhân, có thể giúp cải thiện thêm sự hiểu biết của bạn về tập dữ liệu.
Ví dụ về phân tích theo thời gian:
Hình dưới đây hiển thị số chuyến tàu trung bình mỗi giờ bắt nguồn từ và kết thúc tại một địa điểm cụ thể dựa trên bộ dữ liệu mô phỏng
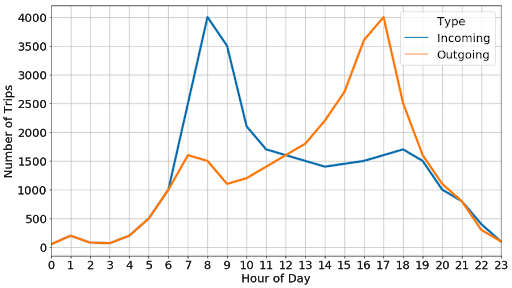
Từ đó, chúng ta có thể kết luận rằng thời gian cao điểm là vào khoảng 8:30 sáng và 5:30 chiều, điều này phù hợp với trực giác rằng đây là những lúc mọi người thường rời khỏi nhà vào buổi sáng và trở về sau một ngày làm việc.
Lựa chọn tính năng và kĩ thuật
Mục tiêu cuối cùng của EDA (dù nghiêm ngặt hay thông qua trực quan hóa) là cung cấp những hiểu biết sâu sắc về bộ dữ liệu mà bạn đang nghiên cứu. Điều này có thể truyền cảm hứng cho việc lựa chọn tính năng, kỹ thuật và quy trình xây dựng mô hình tiếp theo của bạn.
Phân tích mô tả cung cấp số liệu thống kê cơ bản của từng thuộc tính của bộ dữ liệu. Những thống kê đó có thể giúp bạn xác định các vấn đề sau:
- Tỷ lệ phần trăm cao bị thiếu
- Phương sai số thấp
- Entropy thấp của các thuộc tính phân loại
- Mất cân bằng mục tiêu phân loại (mất cân bằng lớp học)
- Phân phối xiên các thuộc tính số
- Cardinality cao của các thuộc tính phân loại
Phân tích tương quan kiểm tra mối quan hệ giữa hai thuộc tính. Có hai điểm hành động điển hình được kích hoạt bởi phân tích tương quan trong bối cảnh lựa chọn tính năng hoặc kỹ thuật tính năng:
- Tương quan thấp giữa tính năng và mục tiêu
- Tương quan cao giữa các tính năng
Sau khi bạn xác định được các vấn đề, nhiệm vụ tiếp theo là đưa ra quyết định hợp lý về cách giảm thiểu đúng các vấn đề này. Một ví dụ như vậy là cho phần trăm cao của các giá trị bị thiếu. Vấn đề được xác định là thuộc tính bị thiếu trong một tỷ lệ đáng kể của các điểm dữ liệu. Ngưỡng hoặc định nghĩa của tầm quan trọng có thể được đặt dựa trên kiến thức tên miền. Có hai lựa chọn để xử lý việc này, tùy thuộc vào kịch bản kinh doanh:
- Gán một giá trị duy nhất cho các bản ghi giá trị bị thiếu, nếu giá trị còn thiếu, trong các bối cảnh nhất định, thực sự có ý nghĩa. Ví dụ: một giá trị bị thiếu có thể chỉ ra rằng một quy trình cơ bản được giám sát không hoạt động đúng.
- Hủy bỏ tính năng nếu các giá trị bị thiếu do cấu hình sai, các vấn đề về thu thập dữ liệu hoặc lý do ngẫu nhiên không thể kiểm soát được và dữ liệu lịch sử có thể được khôi phục.
Bạn có thể kiểm tra whitepaper để tìm hiểu thêm về các cách giải quyết các vấn đề nêu trên, khuyến nghị trực quan hóa từng phân tích và khảo sát các công cụ hiện có phù hợp nhất.
Một số công cụ giúp bạn tự động hóa
Để tiếp tục giúp bạn tăng tốc quá trình chuẩn bị dữ liệu cho máy học, bạn có thể sử dụng Công cụ đề xuất tính năng và khám phá dữ liệu tự động của Google để tự động hóa phân tích được đề xuất bất kể quy mô của dữ liệu và tạo báo cáo được tổ chức tốt để trình bày kết quả và các khuyến nghị.
Công cụ EDA tự động hóa bao gồm:
- Descriptive analysis of each attribute in a dataset for numerical, categorical;
- Phân tích tương quan của hai thuộc tính (số so với số, số so với phân loại và phân loại so với phân loại) thông qua phân tích định tính và / hoặc định lượng.
Dựa trên EDA được thực hiện, công cụ đưa ra các đề xuất tính năng và tạo một báo cáo tóm tắt, trông giống như thế này:
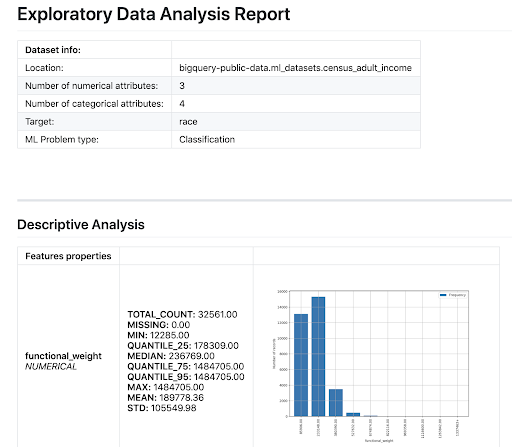
Nguồn: Gimasys
Bài viết liên quan


