
Trong quá trình vận hành, các chuỗi hoạt động như họp trực tuyến, đào tạo…
Có nên chạy cơ sở dữ liệu trên Kubernetes hay không: cần xem xét những điểm gì

Càng ngày càng có nhiều các ứng dụng được triển khai trong các container trên Kubernetes — đến mức chúng ta đã nghe thấy là Kubernetes được gọi là Linux của đám mây. Mặc dù với sự tăng trưởng trên lớp ứng dụng như vậy, lớp dữ liệu lại không bị tác động nhiều từ việc container hóa. Điều này không có gì đáng ngạc nhiên, vì khối lượng công việc được đóng gói trong container phải có khả năng tự phục hồi để khởi động lại, mở rộng ra, ảo hóa và còn những ràng buộc khác. Vì vậy việc kiểm soát những thứ có dạng trạng thái (cơ sở dữ liệu), tính sẵn sàng cho những lớp khác của ứng dụng, và tính dự phòng cho một cơ sở dữ liệu có thể có rất nhiều yêu cầu cụ thể. Những điều này tạo nên những thách thức để chạy cơ sở dữ liệu trên một môi trường phân tán.
Tuy nhiên lớp dữ liệu đang được chú ý nhiều hơn vì có rất nhiều các người phát triển muốn coi hạ tầng dữ liệu tương tự như ngăn xếp ứng dụng. Những người vận hành muốn sử dụng những công cự tương tự cho cơ sở dữ liệu và ứng dụng, và nhận được những lợi ích như trên lớp ứng dụng tại lớp dữ liệu: tăng số lượng nhanh chóng và lặp lại giữa các môi trường. Trong bài viết này, Google sẽ khám phá khi nào và loại cơ sở dữ liệu này có thể chạy hiệu quả trên Kubernetes.
Lựa chọn có thể chạy cơ sở dữ liệu trên Google Cloud Platform
Trước khi chúng ta đào sâu vào những cân nhắc để chạy cơ sở dữ liệu trên Kubernetes, Hãy nhìn lại những lựa chọn mà chúng ta có thể chạy cơ sở dữ liệu trên Google Cloud Platform (GCP) và những gì mà nó sử dụng tốt nhất.
- Cơ sở dữ liệu đã được vận hành đầy đủ (Fully managed databases): Bao gồm Cloud Spanner, Cloud Bigtable và Cloud SQL, trong số những thứ khác. Đây là tùy chọn mức độ tự vận hành thấp từ bạn, vì Google Cloud đã kiểm soát hết tất cả những tác vụ vận hành, như là sao lưu, nâng cấp và mở rộng. Là một người phát triển hay người vận hành, bạn không cần phải phiền với chúng. Bạn chỉ cần tạo cơ sở dữ liệu, xây dựng ứng dụng của bạn và để Google Cloud mở rộng quy mô cho bạn. Điều này cũng có nghĩa là bạn có thể không có quyền truy cập vào phiên bản chính xác của cơ sở dữ liệu, tiện ích mở rộng hoặc kiểm soát chính xác của cơ sở dữ liệu mà bạn muốn.
- Tự làm trên máy ảo: Điều này tốt nhất có thể được mô tả là tùy chọn tự vận hành hoàn toàn, bạn sẽ chịu trách nhiệm hoàn toàn cho việc xây dựng cơ sở dữ liệu của mình, nhân rộng nó, quản lý độ tin cậy, thiết lập sao lưu và hơn thế nữa. Tất cả điều đó có thể là rất nhiều công việc, nhưng bạn có tất cả các tính năng và kiểm soát cơ sở dữ liệu theo ý của bạn.
- Chạy cơ sở dữ liệu trên Kubernetes. Chạy một cơ sở dữ liệu trên Kubernetes gần hơn với tùy chọn tự vận hành, nhưng bạn có được một số lợi ích về mặt tự động hóa mà Kubernetes cung cấp để duy trì ứng dụng cơ sở dữ liệu. Điều đó nói rằng, điều quan trọng cần nhớ là các pod (các container chứa ứng dụng cơ sở dữ liệu) là nhất thời, vì vậy khả năng khởi động lại hoặc thất bại của ứng dụng cơ sở dữ liệu cao hơn. Ngoài ra, một số tác vụ quản trị dành riêng cho cơ sở dữ liệu khác-sao lưu, mở rộng, điều chỉnh, v.v.- là khác nhau vì các lớp ảo được thêm vào đi kèm với container.
Mẹo để chạy cơ sở dữ liệu của bạn trên Kubernetes
Khi chọn đi xuống tuyến đường Kubernetes, hãy suy nghĩ về cơ sở dữ liệu nào bạn sẽ chạy, và nó sẽ hoạt động tốt như thế nào khi đánh đổi trước đó. Vì các pods là trọng yếu, nên khả năng xảy ra các sự kiện chuyển đổi dự phòng cao hơn một cơ sở dữ liệu được lưu trữ hoặc quản lý đầy đủ theo truyền thống. Sẽ dễ dàng hơn để chạy cơ sở dữ liệu trên Kubernetes nếu nó bao gồm các khái niệm như bảo vệ, tự bầu cử dự phòng và sao chép được tích hợp vào DNA của nó (ví dụ: ElasticSearch, Cassandra hoặc MongoDB). Một số các dự án mã nguồn mở cung cấp tài nguyên tùy chọn và người vận hành để giúp quản lý cơ sở dữ liệu.
Tiếp theo, hãy xem xét chức năng mà cơ sở dữ liệu đang thực hiện trong bối cảnh ứng dụng và doanh nghiệp của bạn. Cơ sở dữ liệu đang lưu trữ nhiều lớp tạm thời và bộ đệm phù hợp hơn với Kubernetes. Các lớp dữ liệu loại đó thường có khả năng phục hồi cao hơn được tích hợp vào các ứng dụng, giúp mang lại trải nghiệm tổng thể tốt hơn.
Cuối cùng, hãy chắc chắn rằng bạn hiểu các chế độ sao chép có sẵn trong cơ sở dữ liệu. Các chế độ sao chép không đồng bộ sẽ chừa chỗ cho mất dữ liệu, vì các giao dịch có thể được cam kết với cơ sở dữ liệu chính nhưng không phải cho (các) cơ sở dữ liệu thứ cấp. Vì vậy, hãy chắc chắn để hiểu liệu bạn có thể chịu mất dữ liệu hay không và mức độ chấp nhận được trong bối cảnh ứng dụng của bạn.
Sau khi đánh giá tất cả những cân nhắc đó, bạn sẽ kết thúc với một cây quyết định trông giống như thế này:
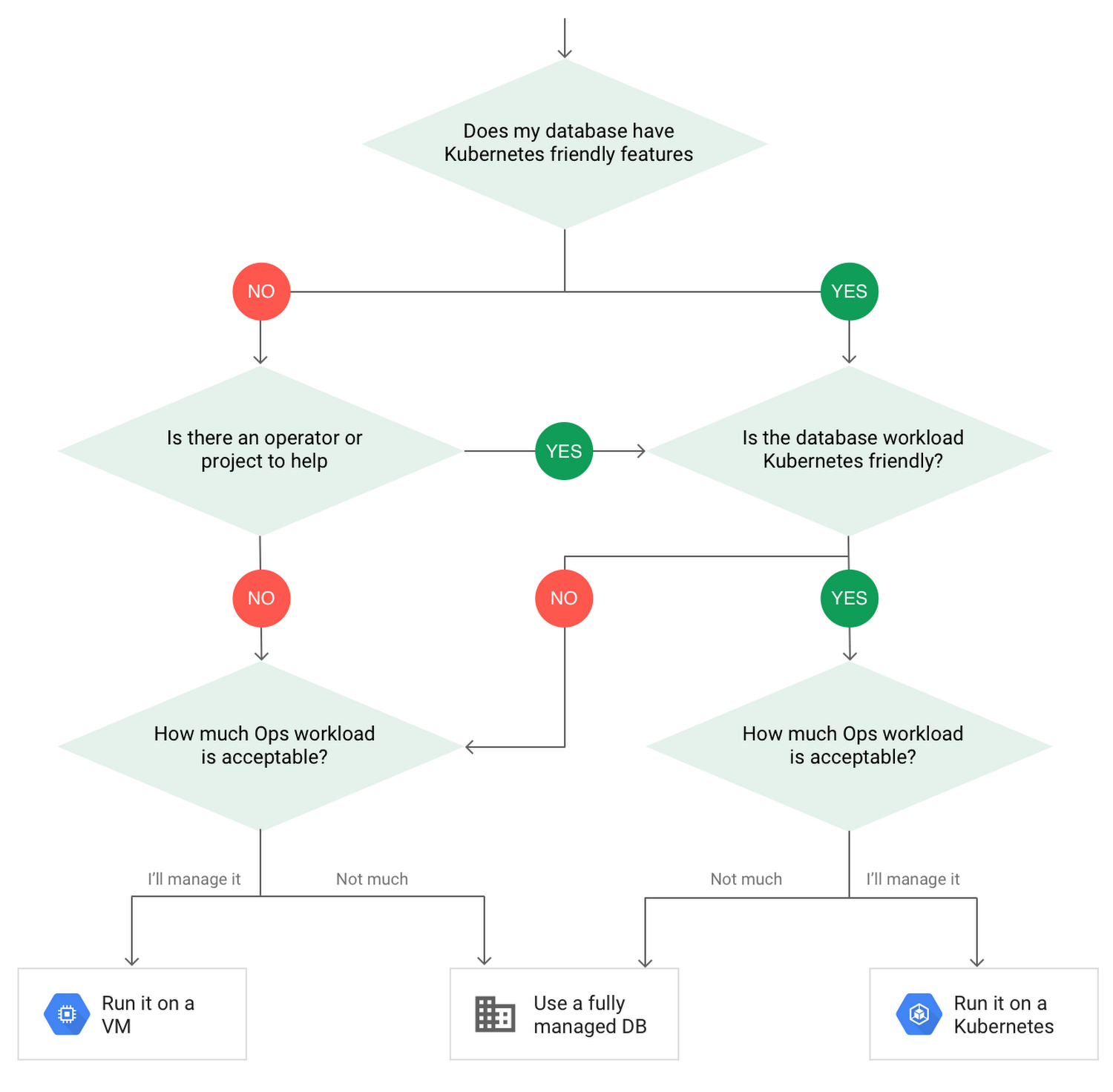
Cách triển khai cơ sở dữ liệu trên Kubernetes
Cách triển khai cơ sở dữ liệu trên Kubernetes bằng StatefulSets
Bây giờ, hãy cùng đào sâu vào chi tiết hơn về cách triển khai cơ sở dữ liệu trên Kubernetes bằng StatefulSets. Với Statefulset, dữ liệu của bạn có thể được lưu trữ trên các khối vĩnh viễn, tách ứng dụng cơ sở dữ liệu khỏi bộ lưu trữ vĩnh viễn, do đó, khi một pods (như ứng dụng cơ sở dữ liệu) được tạo lại, tất cả dữ liệu vẫn ở đó. Ngoài ra, khi một pod được tạo lại trong Statefulset, nó sẽ giữ cùng tên, do đó bạn cần có một điểm cuối nhất quán để kết nối. Dữ liệu vĩnh viễn và đặt tên nhất quán là hai trong số những lợi ích lớn nhất của StatefulSets. Bạn có thể kiểm tra các tài liệu chi tiết về Kubernetes.
Nếu bạn cần chạy một cơ sở dữ liệu không phù hợp với mô hình của cơ sở dữ liệu thân thiện với Kubernetes (như MySQL hoặc PostgreQuery), hãy cân nhắc sử dụng trình điều khiển Kubernetes hoặc các dự án bao bọc các cơ sở dữ liệu đó bằng các tính năng bổ sung. Trình điều khiển sẽ giúp bạn tạo ra các cơ sở dữ liệu đó và thực hiện các nhiệm vụ bảo trì cơ sở dữ liệu như sao lưu và sao chép. Đối với MySQL nói riêng, hãy xem Trình điều khiển Oracle MySQL và Crunchy Data for PostgreSQL. .
Trình điều khiển sử dụng các tài nguyên và bộ điều khiển tùy chỉnh để hiển thị các hoạt động dành riêng cho ứng dụng thông qua API Kubernetes. Ví dụ: để thực hiện sao lưu bằng Crunchy Data, chỉ cần thực hiện pgo backup [cluster_name].Để thêm một bản sao Postgres, sử dụng pgo scale cluster [cluster_name].
Có một số dự án khác ngoài đó mà bạn có thể khám phá, chẳng hạn như Patroni cho PostgreSQL. Các dự án này sử dụng các trình điều khiển, nhưng tiến thêm một bước. Họ đã xây dựng nhiều công cụ xung quanh cơ sở dữ liệu tương ứng để hỗ trợ hoạt động điều khiển của họ bên trong Kubernetes. Chúng có thể bao gồm các tính năng bổ sung như bảo vệ, bầu chọn nhà lãnh đạo và chức năng chuyển đổi dự phòng cần thiết để triển khai thành công MySQL hoặc PostgreQuery trong Kubernetes.
Mặc dù việc chạy một cơ sở dữ liệu trong Kubernetes đang đạt được những bước tiến, nó vẫn còn xa so với một khoa học chính xác. Có rất nhiều công việc đang được thực hiện trong lĩnh vực này, vì vậy hãy chú ý khi các công nghệ và công cụ phát triển theo hướng làm cho việc chạy cơ sở dữ liệu trong Kubernetes trở nên bình thường hơn nhiều.
Khi bạn đã sẵn sàng để bắt đầu, hãy xem GCP Marketplace để triển khai dễ dàng SaaS, máy ảo, và các giải pháp cơ sở dữ liệu được container hóa và trình điều khiển có thể được triển khai trên GCP hoặc cụm Kubernetes ở bất cứ đâu.
Nguồn: Gimasys
Bài viết liên quan


