
Trong quá trình vận hành, các chuỗi hoạt động như họp trực tuyến, đào tạo…
Whether to run a database on Kubernetes: what to consider

More and more applications are deployed in the above containers Kubernetes — so much so that we have heard that Kubernetes is called the Linux of the cloud. Although with such growth on the application layer, the data layer is not affected much by containerization. This is not surprising, as containerized workloads must be self-healing for restart, scaling, virtualization, and other constraints. So controlling things like state (database), availability for other layers of the application, and redundancy for a database can have a lot of specific requirements. These create challenges to run the database on a distributed environment.
However, the data layer is getting more attention because many developers want to treat the data infrastructure as similar to the application stack. Operators want to use the same tools for databases and applications, and get the same benefits as application-layer at data-layer: rapid and repeatable volume growth between environments. In this article, Google will explore when and how this type of database can run efficiently on Kubernetes.
Option to be able to run the database on Google Cloud Platform
Before we dig into the considerations for running a database on Kubernetes, let's take a look at the options we can run the database on. Google Cloud Platform (GCP) and what it uses best.
- Fully managed databases: Including Cloud Spanner, Cloud Bigtable and Cloud SQL, among different things. This is a low autonomy option for you, as Google Cloud already controls all operational tasks, such as backups, upgrades, and expansions. As a developer or operator, you don't have to bother with them. You simply create your database, build your application, and let Google Cloud scale for you. This also means that you may not have access to the exact version of the database, the extension, or the exact control of the database that you want.
- Do-it-yourself on a virtual machine: This can best be described as a fully self-hosted option where you will take full responsibility for building your database, scaling it, managing reliability trust, set up backups, and more. All of that can be a lot of work, but you have all the features and control of the database at your disposal.
- Run the database on Kubernetes. Running a database on Kubernetes is closer to being self-sustaining, but you get some of the automation benefits that Kubernetes provides for maintaining database applications. That said, it's important to remember that pods (containers containing database applications) are transient, so the chances of a database application restart or failure are higher. Additionally, some of the other database-specific administrative tasks—backup, scaling, tuning, etc.—are different because of the added virtual layers that come with the container.
Tips for running your database on Kubernetes
When choosing to go down the Kubernetes route, think about what database you'll be running, and how well it will perform given the trade-offs beforehand. Because pods are critical, the likelihood of failover events is higher than a traditionally fully managed or hosted database. It would be easier to run a database on Kubernetes if it included concepts like protection, self-selection, and replication built into its DNA (e.g. ElasticSearch, Cassandra or MongoDB). Some of the open source projects provide optional resources and operators to help with database management.
Next, consider the functionality the database is performing in the context of your application and business. The database is caching multiple layers of temporary and caching is more suitable for Kubernetes. Data layers of that type often have more resilience built into applications, which results in a better overall experience.
Finally, make sure you understand the replication modes available in the database. Asynchronous replication modes leave room for data loss, as transactions can be committed to the primary database but not to the secondary database(s). So be sure to understand whether you can tolerate data loss and how much is acceptable in the context of your application.
After evaluating all of those considerations, you'll end up with a decision tree that looks something like this:
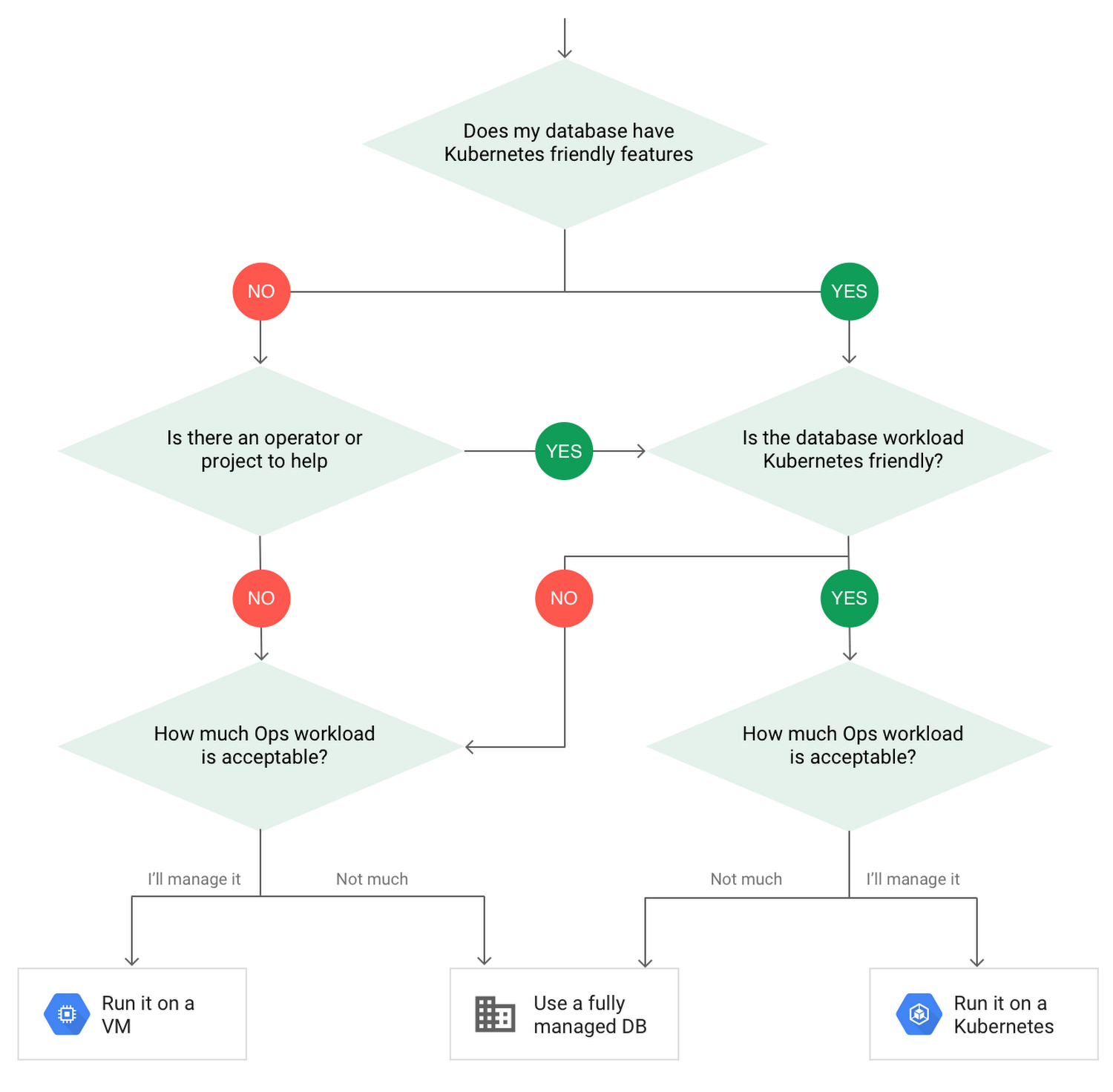
How to deploy a database on Kubernetes
How to Deploy Database on Kubernetes Using StatefulSets
Now, let's dig into more detail on how to deploy a database on Kubernetes using StatefulSets. With StatefulSet, your data can be stored on permanent blocks, separating the database application from the permanent storage, so when a pod (like a database application) is recreated , all the data is still there. Also, when a pod is recreated in a Statefulset, it will keep the same name, so you need a consistent endpoint to connect to. Persistent data and consistent naming are two of the biggest benefits of StatefulSets. You can check the detailed documentation about Kubernetes.
If you need to run a database that doesn't fit the model of a Kubernetes-friendly database (like MySQL or PostgreSQL), consider using the Kubernetes driver or the projects that wrap the databases whether it by extra features. Drivers will help you create those databases and perform database maintenance tasks such as backups and replication. For MySQL in particular, see Oracle MySQL Driver and Crunchy Data for PostgreSQL. .
Drivers use the resources and a custom controller to expose application-specific activities via the Kubernetes API. For example, to perform a backup using Crunchy Data, simply do pgo backup [cluster_name].To add a Postgres copy, use pgo scale cluster [cluster_name].
There are some other projects out there that you can explore such as Patroni for PostgreSQL. These projects use drivers, but go a step further. They have built many tools around their respective databases to support their control operation inside Kubernetes. These may include additional features such as protection, leader election, and failover functionality required to successfully deploy MySQL or PostgreSQL in Kubernetes.
Although running a database in Kubernetes is making strides, it is still far from an exact science. There is a lot of work being done in this area, so watch out as technologies and tools evolve towards making it much more normal to run databases in Kubernetes.
When you're ready to get started, watch GCP Marketplace for easy deployment of SaaS, virtual machines, and driver and containerized database solutions that can be deployed on GCP or Kubernetes clusters anywhere.
Source: Gimasys
Related Posts


