
Điện toán đám mây (Cloud Computing) đã trở thành vấn đề cốt lõi cho hạ…
Cách theo dõi tình trạng các nhóm VM trong Google Compute Engine console
Nhiều công ty cung cấp dịch vụ về infrastructure cần quản lý các nhóm máy ảo lớn. Nhiệm vụ này thường liên quan đến việc thu thập các tín hiệu khác nhau, xác định các điểm ngoại lệ, đi sâu vào tìm nguyên nhân và khắc phục sự cố. Đây thường là một quá trình tốn thời gian cho người vận hành vì họ cần chuyển đổi giữa nhiều trang để thu thập thông tin cần thiết.
Chúng tôi rất vui mừng thông báo rằng Observability tab trong trang VM List page của Compute Engine console đã đạt được phổ cập chung. Observability tab là một cách dễ dàng để theo dõi và điều chỉnh hiện trạng của nhóm máy ảo — tab này cung cấp các số liệu về tình trạng chính và ghi log ngay khi sử dụng, cũng như làm nổi bật các điểm bất thường trong hệ thống của bạn. Bạn có thể nhanh chóng hiểu rõ hơn về CPU, memory, network, disk, live processes, system events và live logs trong cùng một giao diện.
Observability tab ở chế độ xem fleet level
Chế độ xem fleet level này cho phép bạn hiểu các VM của mình một cách toàn diện hơn bằng cách 1) xác định các outliers của VM dựa trên các chỉ số chính như CPU, Ram và 2) xem xu hướng cross-fleet xung quanh các tài nguyên chính hoặc độ trễ mạng theo vị trí.
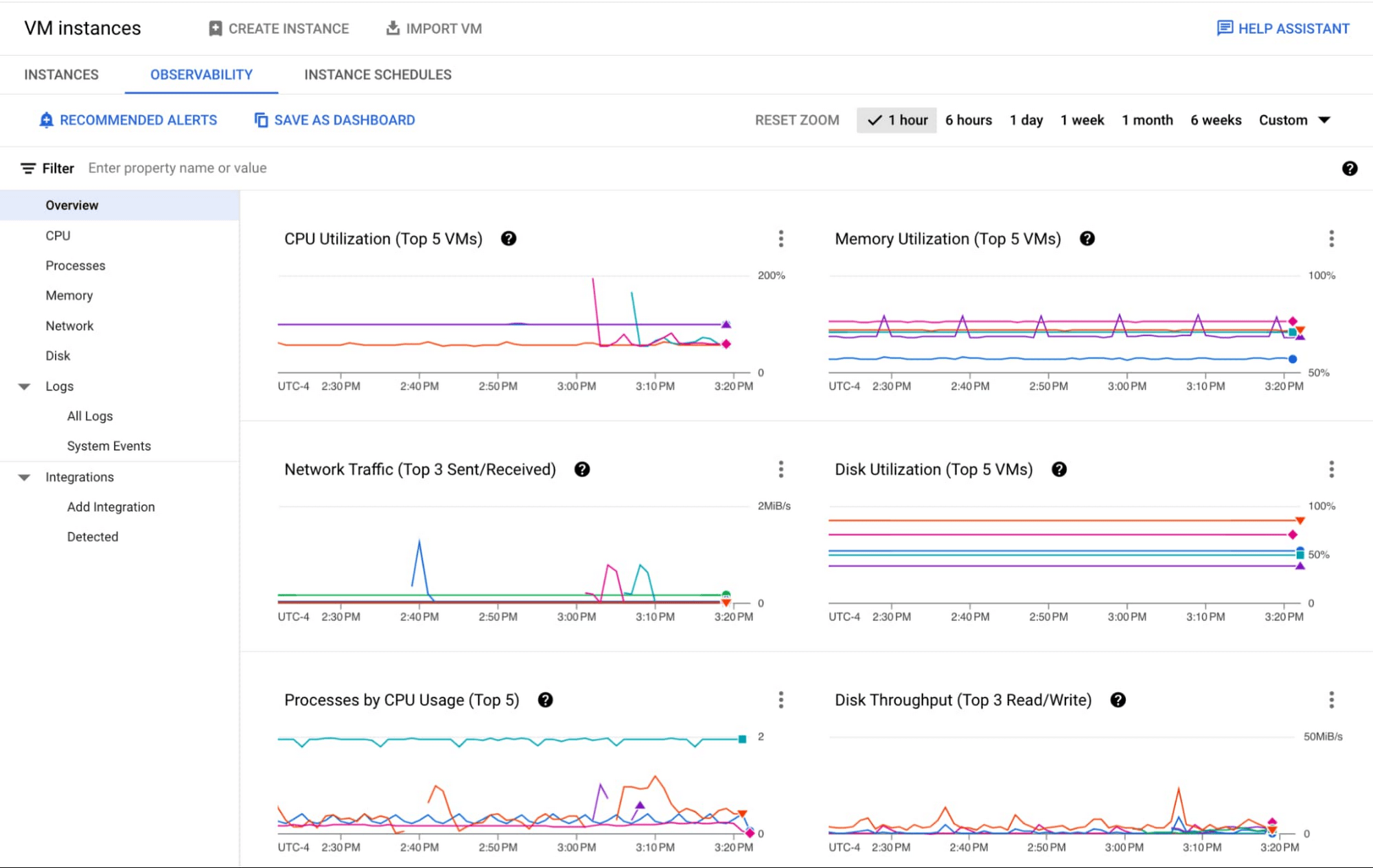
Chỉ số đo lường
Observability tab giúp bạn trực quan hóa các số liệu mà không cần cấu hình. Dưới đây là tất cả các chỉ số được cung cấp sẵn và ví dụ về các trường hợp sử dụng của chúng:
CPU
- CPU Utilization, vCPU Core Usage: Khắc phục sự cố về hiệu suất của ứng dụng bằng cách xác định các máy ảo đang sử dụng hết tài nguyên CPU. Troubleshooting VM Performance
- Processes by CPU Usage: Xác định các quy trình hàng đầu theo mức sử dụng CPU để xác định nguyên nhân cốt lõi của sự cố hoặc để xác định các cơ hội tối ưu hóa.
- System Load per vCPU: Nếu con số này gần bằng 1, điều đó có thể cho thấy bạn cần phải mở rộng quy mô máy ảo của mình để tránh các sự cố về hiệu suất.
- Unused vCPU Cores: Khám phá các cơ hội tiết kiệm chi phí từ các máy ảo đang sử dụng ít tài nguyên CPU
Processes
- Live processes by CPU Usage, Memory Usage, Disk Throughput: Xác định các quy trình hàng đầu theo CPU, Memory, hoặc Disk Throughput để tìm các cơ hội tối ưu hóa tài nguyên.
- Live processes by CPU per VM, Processes by Memory per VM, Processes by Disk Throughput per VM: Tìm các sample VMs đang chạy các tiến trình ngốn nhiều CPU/Memory/Disk nhất
Memory
- Memory Utilization, Memory Bytes Used: Khắc phục sự cố về hiệu suất của ứng dụng bằng cách xác định các máy ảo sắp hết Memory
- Memory Bytes Unused: Khám phá các cơ hội tiết kiệm chi phí từ các máy ảo đang sử dụng ít tài nguyên Memory
- Processes by Memory: Xác định các quy trình hàng đầu bằng cách sử dụng Memory
- Memory by State (across VMs): Tìm hiểu kích thước tổng hợp của bộ nhớ miễn phí, đã sử dụng, đã lưu vào bộ nhớ cache, bộ đệm và slab memory trong nhóm của bạn
Network
- Network Traffic: Xác định “top talker” trong hệ thống của bạn để tối ưu hóa chi phí
- Sent Traffic by Destination Type (GCP/External/Google), Sent External (or different project), Sent Cross-region và cross-zone: Khám phá những đóng góp giúp chi phí mạng hàng đầu (xem Network costs)
- RTT by Destination Type (GCP/External/Google): Khắc phục sự cố về hiệu suất của ứng dụng bằng cách xác định độ trễ bất thường (RTT)
- Firewall Packets Denied (Highest Variance): Phát hiện sự bất thường trong lưu lượng truy cập đến (ví dụ: lưu lượng truy cập bị từ chối tăng đột ngột)
Disk
- Disk Utilization: Khắc phục sự cố về hiệu suất của ứng dụng bằng cách xác định các máy ảo sắp hết dung lượng Disk
- Disk Throughput, Disk IOPS: Theo dõi hiệu suất của Disk bằng cách xem các máy ảo ngoại lệ trên thông lượng và IOPS.
- I/O Size, I/O Latency, Queue length, CPU I/O Wait %: Đi sâu hơn vào các vấn đề về hiệu suất I/O của Disk bằng cách xem kích thước I/O, độ trễ và độ dài hàng đợi. Optimizing persistent disk performance để biết cách điều chỉnh workloads của bạn để có hiệu suất tối đa trên các thứ nguyên này.
Ghi chú: Nhiều chỉ số như CPU và mạng được cung cấp miễn phí và được thu thập tự động bởi cơ sở hạ tầng Compute Engine. Các số liệu khác như bộ nhớ, disk utilization và processes cần Ops Agent và có thể bị tính phí (Cloud Monitoring Non-chargeable and Chargeable Metrics).
Logs
Phần Logs cung cấp out-of-the-box logs từ nhóm VM của bạn và bạn có thể dễ dàng filter log theo từ khóa, VM ID, severity level, hoặc suggested queries. Bạn cũng có thể hiểu rõ hơn về các system events quan trọng, chẳng hạn như host machine maintenance events (Live Migrations hoặc host errors), Spot VMs preemptions, v.v.
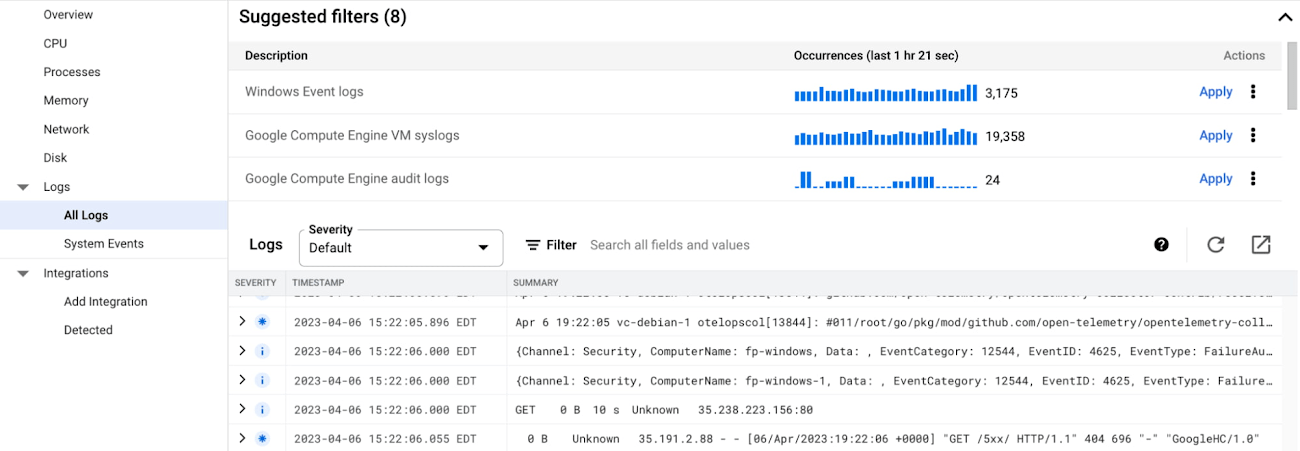 Nếu bạn cần log analysis nâng cao hơn, chỉ cần nhấp vào biểu tượng trên cùng bên phải để điều hướng đến Cloud Logging – fully managed, real-time log management với storage, search, analysis và alerting ở quy mô exabyte scale.
Nếu bạn cần log analysis nâng cao hơn, chỉ cần nhấp vào biểu tượng trên cùng bên phải để điều hướng đến Cloud Logging – fully managed, real-time log management với storage, search, analysis và alerting ở quy mô exabyte scale.
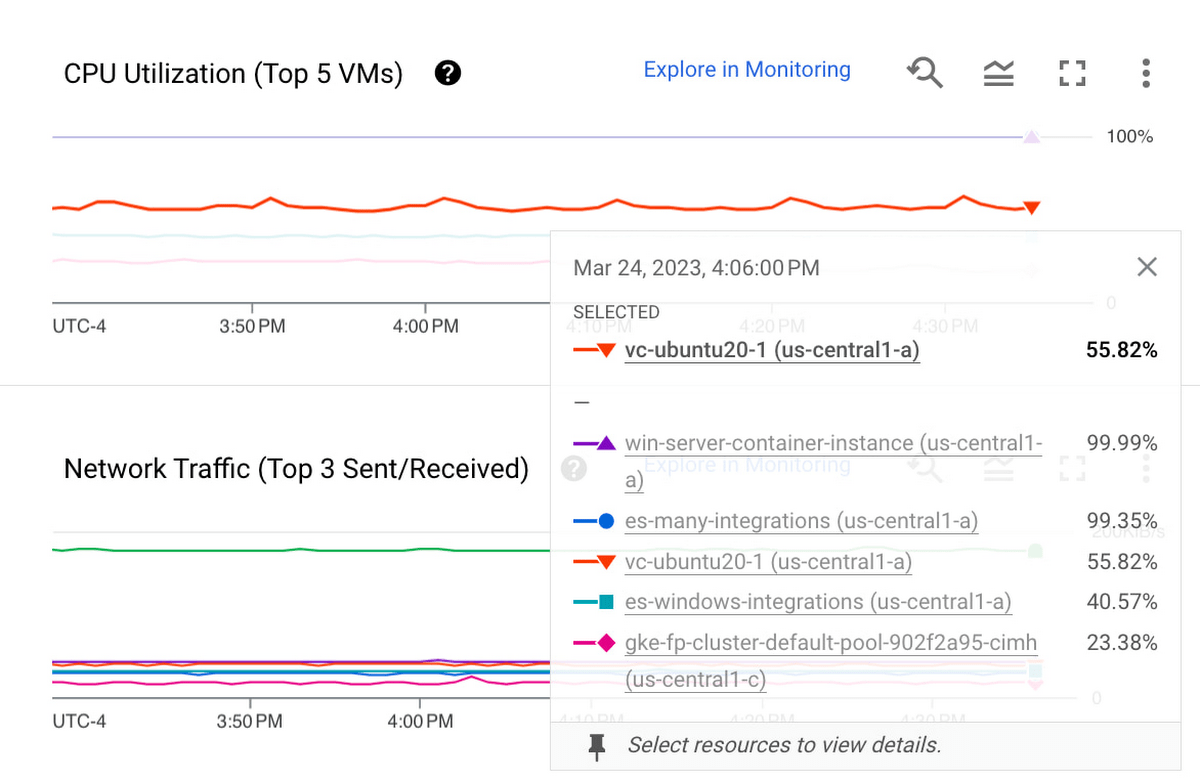
Tìm hiểu, phân tích một VM duy nhất
Để troubleshoot một VM cụ thể, bạn có thể nhấp vào biểu đồ để ghim thẻ di chuột, sau đó nhấp vào máy ảo mà bạn muốn điều tra, như minh họa bên dưới:
 Sau khi nhấp vào VM, bạn sẽ tìm thấy các thông tin chi tiết về VM như sau – metrics, logs, processes, open incidents, uptime check, shortcuts to SSH to hoặc manage the VM, v.v
Sau khi nhấp vào VM, bạn sẽ tìm thấy các thông tin chi tiết về VM như sau – metrics, logs, processes, open incidents, uptime check, shortcuts to SSH to hoặc manage the VM, v.v
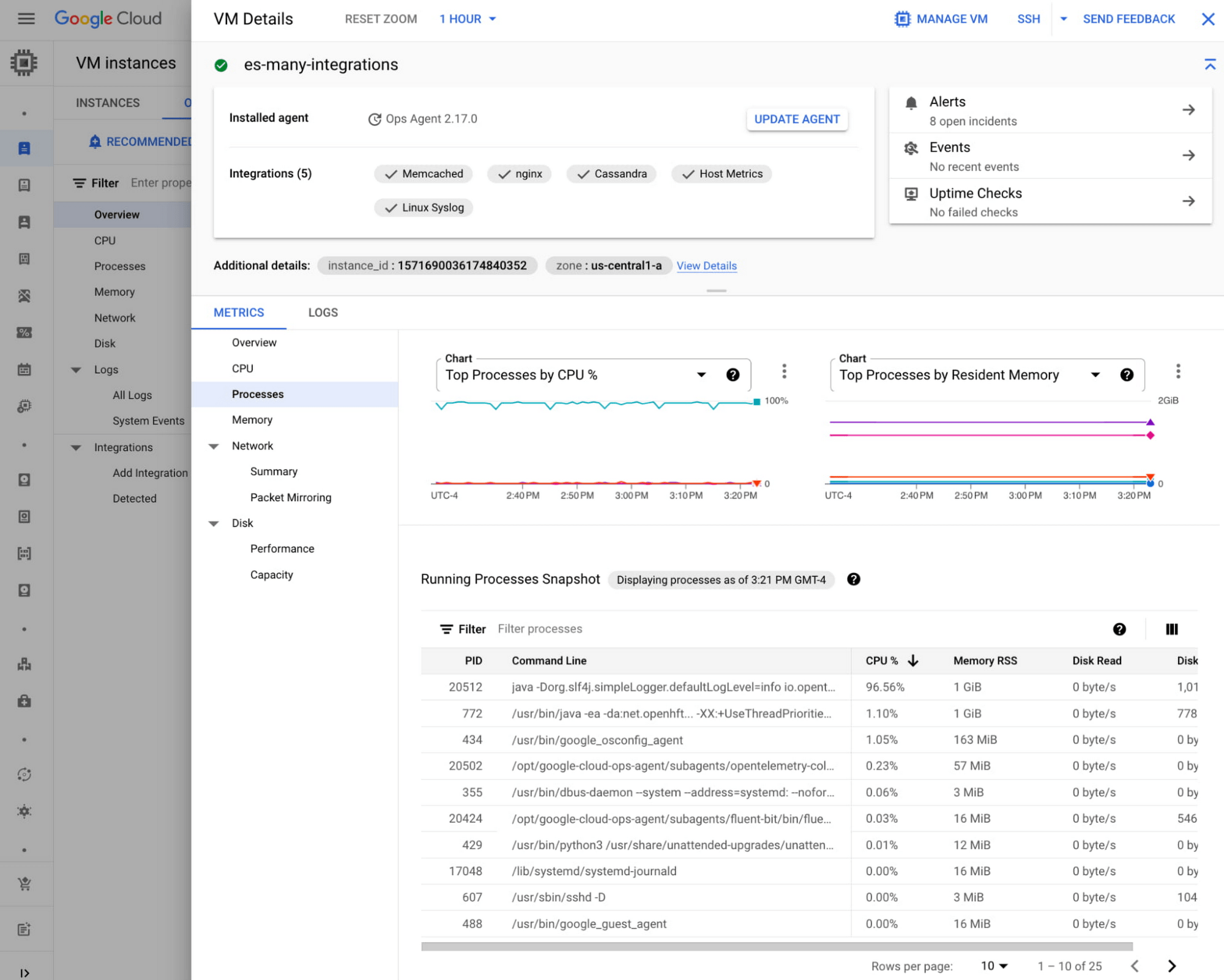
Tích hợp ứng dụng
Ngoài cơ sở hạ tầng, bạn cũng có thể bắt đầu monitoring các ứng dụng của mình như NGINX hoặc MySQL tại đây trong Observability tab. Các Application Integrations hướng dẫn bạn giám sát các ứng dụng của bên thứ ba bằng Ops Agent. Đối với mỗi integrations, bạn có thể tìm hiểu thêm về các chỉ số được thu thập, hướng dẫn configuration và cấu hình các dashboards đơn giản.
Khám phá các Alert Policies được đề xuất
Bạn có muốn nhận thông báo khi có sự cố xảy ra với máy ảo của mình không?
Recommended Alerts này cung cấp các out-of-the-box alert policy templates trên các chỉ số health metrics, chẳng hạn như mức sử dụng CPU và memory utilization. Bạn có thể thiết lập các policies này trên toàn bộ nhóm của mình chỉ bằng một vài cú nhấp chuột.
Cloud đã và đang là xu hướng tất yếu trong hệ thống phát triển , tối ưu công nghệ của các doanh nghiệp. Gimasys – Premier Partner của Google tại Việt Nam là đơn vị cung cấp, tư vấn các cấu trúc, thiết kế giải pháp Cloud tối ưu cho bạn. Để biết được hỗ trợ về mặt chuyên môn kỹ thuật, bạn có thể liên hệ Gimasys – Premier Partner của Google tại Việt Nam theo thông tin:
- Hotline: 0974 417 099 (HCM) | 0987 682 505 (HN)
- Email: gcp@gimasys.com
Nguồn: Gimasys
Bài viết liên quan


