Hôm nay, Google rất vui mừng thông báo về việc chính thức ra mắt tài…
Colossus under the hood: How we deliver SSD performance at HDD prices
From YouTube and Gmail to BigQuery and Cloud Storage, almost all of Google’s products depend on Colossus, our foundational distributed storage system. As Google’s universal storage platform, Colossus achieves throughput that rivals or exceeds the best parallel file systems, has the management and scale of an object storage system, and an easy-to-use programming model that’s used by all Google teams. Moreover, it does all this while serving the needs of products with incredibly diverse requirements, be it scale, affordability, throughput, or latency.
| Application | I/O sizes | Expected performance |
| BigQuery scans | hundreds of KBs to tens of MBs | TB/s |
| Cloud Storage - standard | KBs to tens of MBs | 100s of milliseconds |
| Gmail messages | less than hundreds of KBs | 10s of milliseconds |
| Gmail attachments | KBs to MBs | seconds |
| Hyperdisk reads | KBs to hundreds of KBs | <1 ms |
| YouTube video storage | MB | seconds |
Colossus’ flexibility shows up in a number of publicly available Google Cloud products. Hyperdisk ML utilizes Colossus solid state disk (SSD) to support 2,500 nodes reading at 1.2 TB/s — impressive scalability. Spanner uses Colossus to address cheap HDD storage with super-fast SSD storage in the same filesystem, the foundation of its tiered storage feature. Cloud Storage uses Colossus SSD caching to deliver the cheapest storage while still supporting the intensive I/O of demanding AI/ML applications. Finally, BigQuery’s Colossus-based storage provides super-fast I/O to extra-large queries.
We last wrote about Colossus some time ago and wanted to give you some insights on how its capabilities support Google Cloud’s changing business and what new capabilities we’ve added, specifically around support for SSD.
Colossus background
But first, here’s a little background on Colossus:
- Colossus is an evolution of the Google File System (GFS).
- The traditional Colossus filesystem is contained in a single datacenter.
- Colossus simplified the GFS programming model to an append-only storage system that combines file systems’ familiar programming interface with the scalability of object storage.
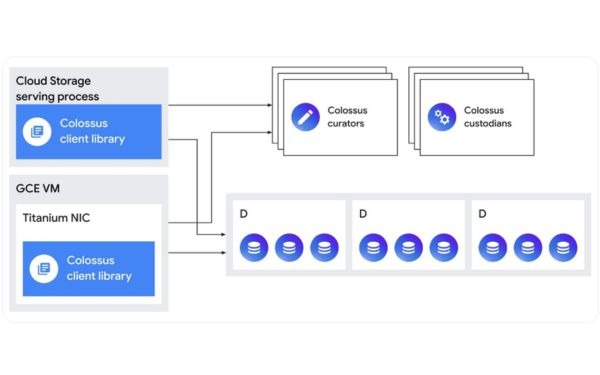
- The Colossus metadata service is made up of
- “curators” that deal with interactive control operations like file creation and deletion
- “custodians,” which maintain the durability and availability of data as well as disk-space balancing.
- Colossus clients interact with curators for metadata and then directly store data on “D servers,” which host its HDDs or SSDs.
Colossus is also a zonal product. Google has built a single Colossus file system for each cluster, an internal building block of a Google Cloud region. Most data centers have one cluster and therefore one Colossus file system, regardless of how many workloads run within that cluster. Many Colossus file systems have multi-exabyte capacities, including two separate file systems that exceed 10 exabytes each. This high scalability ensures that even the most demanding applications do not run out of disk space near the cluster’s compute resources within a region.
These demanding applications also require a large amount of IOPS and throughput. In fact, some of Google’s largest file systems regularly exceed 50 TB/s read throughput and 25 TB/s write throughput. That’s enough throughput to transfer over 100 full-length 8K movies per second!
Google doesn’t rely solely on Colossus to support large streaming I/Os, either. Many applications perform small log writes or small random reads. Their busiest cluster delivered over 600 million IOPS, including both reads and writes.
Of course, to get that much performance, you need to get the data to the right place. It’s hard to read at 50TB/s if all your data is on slow drives. This leads to two key new improvements in Colossus: SSD caching and SSD data locality, both of which are powered by a system Google calls “L4.”
What’s new in Colossus SSD placement?
In a previous blog post about Colossus, Google mentioned how they put the “hottest” data on SSDs and balance the rest of the data across all the devices in the cluster. This is even more important today, as SSDs become more affordable and their role in Google’s data centers increases. No storage designer builds a system entirely out of HDDs anymore.
However, SSD-only storage is still significantly more expensive than a hybrid SSD-HDD storage system. The challenge is to put the right data—the data with the most I/O accesses or the lowest latency requirements—on SSDs, while keeping the majority of data on HDDs.
So how does Colossus determine the most relevant data?
Colossus has several ways to choose the right data to put on the SSD:
- Force the system to put data on SSD: Here, a Colossus internal user can force the system to save data to SSD using the path:
/cns/ex/home/leg/partition=ssd/myfile.
This is the simplest way and ensures that all files are stored on the SSD. However, it is also the most expensive option. - Using hybrid placement: More experienced users can take advantage of “hybrid placement” and tell the Colossus system to place only one copy on the SSD using the path:
/cns/ex/home/leg/partition=ssd.1/myfile.
This is a more cost-effective method, but if server D has an SSD replica that is unavailable, data access will be affected by HDD latency.
- Using L4: For the majority of data at Google, most developers use L4 distributed SSD caching technology, which automatically selects the most appropriate data to place on the SSD.
L4 read caching
The L4 distributed SSD cache analyzes the application's access patterns and automatically places the most appropriate data on the SSD. When acting as a read cache, the L4 index servers maintain a distributed read cache:
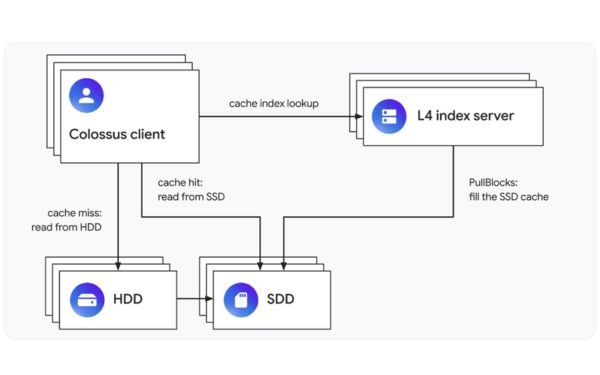
This means that when an application wants to read data, it first checks with an L4 index server. This index server tells the application whether the data is in the cache. If it is, the application reads the data from one or more SSDs. If not, the cache reports a cache miss, and the application fetches the data from the drive where Colossus placed it.
When a cache miss occurs, the L4 may decide to insert the accessed data into the SSD cache. It does this by requesting an SSD host to transfer the data from the HDD host. When the cache is full, the L4 will remove some items from the cache to free up space for new data.
L4 can adjust how “aggressive” it is in placing data on SSDs. Google uses a Machine Learning (ML)-based algorithm to decide the right policy for each workload: put data into the L4 cache as soon as it is written, after the first read, or after a second read in a short period of time.
This approach works well for applications that frequently read the same data, greatly improving IOPS performance and bandwidth. However, it has one major drawback: Google still writes new data to the HDD. In fact, there are other important types of data for which L4 read caching doesn’t save as much resources as it would like, namely data that is written, read, and deleted quickly (such as intermediate results for a large batch job), and database transaction logs and other files with many small appends. Neither of these types of workloads are well suited to HDDs, so it’s better to write them directly to SSDs and skip the HDD altogether.
L4 writeback for Colossus
Now, imagine that an internal user of Colossus wants to put some of their data on an SSD. They need to think carefully about which files should be on the SSD and how much SSD storage they need to purchase for their workload. If they have old files that are no longer being accessed, they may want to move that data from the SSD to the HDD. But Google knows from observing users that deciding on these parameters is difficult. To help users, Google has also improved the L4 service to automate this task.
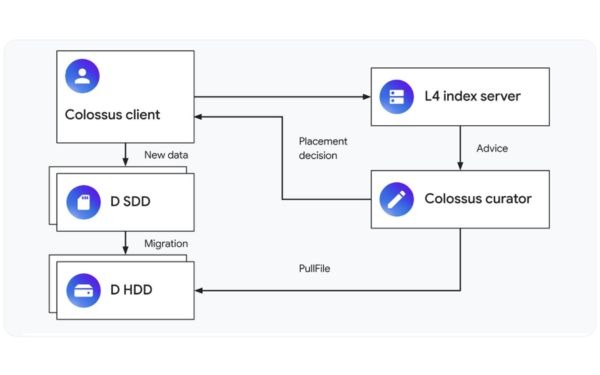 When used as a writeback cache, the L4 service advises Colossus administrators on whether and for how long to place a new file on the SSD. This is a complex issue! When a file is created, Colossus only knows the application that created the file and the file name — it cannot know for sure how the file will be used.
When used as a writeback cache, the L4 service advises Colossus administrators on whether and for how long to place a new file on the SSD. This is a complex issue! When a file is created, Colossus only knows the application that created the file and the file name — it cannot know for sure how the file will be used.
To solve this problem, Google uses the same approach as the L4 read cache described in the CacheSack paper mentioned earlier. The application provides L4 with characteristics such as the file type or metadata about the database column containing the data. L4 uses these characteristics to classify files into “buckets” and observes the I/O patterns of each bucket over time. These I/O patterns are then used to run online simulations with different storage policies, such as “storage on SSD for one hour,” “storage on SSD for two hours,” or “no storage on SSD.” Based on the simulation results, L4 selects the optimal policy for each bucket of data.
These online simulations also serve another important purpose: they predict how L4 will allocate data if there is more or less SSD capacity. This allows Google to calculate how much I/O can be offloaded from HDD to SSD at different SSD capacities. This information helps guide purchases of new SSD hardware and helps planners adjust SSD capacity across applications to optimize performance.
When instructed, Colossus administrators can instruct the system to save new files on the SSD instead of the default HDD. After a certain period of time, if the file still exists, the administrator will move the data from the SSD to the HDD.
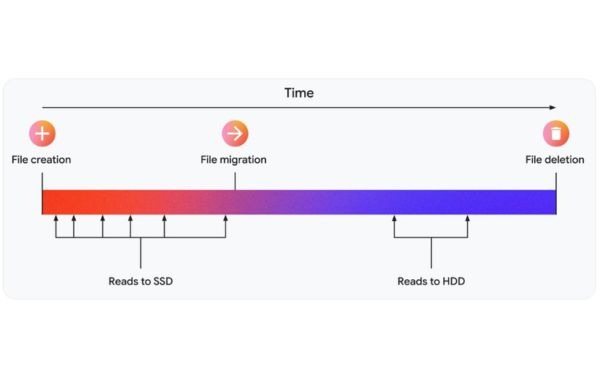 When L4's simulation system accurately predicts file access patterns, Google places only a small portion of the data on SSDs. These SSDs absorb the majority of reads (which typically occur on newly created files) before moving the data to cheaper storage, reducing overall costs.
When L4's simulation system accurately predicts file access patterns, Google places only a small portion of the data on SSDs. These SSDs absorb the majority of reads (which typically occur on newly created files) before moving the data to cheaper storage, reducing overall costs.
In the ideal scenario, the file would be deleted before Google moved it to the HDD, thereby avoiding any I/O operations on the HDD altogether.
Conclusion
In short, Colossus, combined with the infrastructure power of Google Cloud, has realized a breakthrough storage solution that delivers superior SSD performance at a cost comparable to traditional HDDs. This opens up a huge opportunity for businesses, especially those processing large amounts of data and requiring fast access speeds, to optimize storage costs without sacrificing performance. This innovation not only improves operational efficiency but also promotes a strong digital transformation in many fields.
Related Posts