Google đang giới thiệu mục Cuộc họp chuyên dụng trong Google Chat — một cách…
Multi-Region Database Disaster Redundancy Architecture for MySQL
Enterprises expect high reliability of the data storage infrastructure their applications are using. Although you and your team prepare the best technical scenarios, carefully, there is still a risk of database failure, whether the server or network partition fails or not. Good planning can help you respond to problems and recover faster when disaster strikes.
This blog shows a database architecture implementation approach that ensures high resiliency and disaster recovery for MySQL on Compute Engine, using sector disks as well as load balancers.
Any database architecture should have approaches in place for error recovery and rapid recovery from failure without data loss. These methods are demonstrated in the RTO (recovery time objective) and RPO (recovery point objective), which provide ways to set up and then measure how long the service may be unavailable and save the data to be saved. how far.
When a database fails, they should be recovered as quickly as possible with as small an RTO as possible, ideally within seconds. It takes as little data as possible, not even at all. The desired RPO is the final consistent database state.
From a database architecture and implementation design, this can be done with two distinct concepts: high availability and disaster recovery. Use both at the same time to achieve an architecture that prepares for the greatest range of failures or failures.
Create a flexible database architecture
A high availability database architecture has database servers in at least two or more regions. If a server on one region fails or the zone becomes inaccessible, data in other regions is also available for further processing. The figure below shows two cases, one in the zn1 region and the other in the zn2 region. The front-end load balancer assists in directing traffic to a 'healthiest' database available for read and write queries.
A disaster recovery architecture adds a second highest availability database setup in the second area. If one of the zones becomes inaccessible or fails, the other is immediately put into use. The figure below shows two areas, the main area and the DR (disaster recovery) area. Data is copied from the primary to the DR zone so that the DR zone can take over from the latest consistent database state. The load balancer in front of the zones directs traffic to the zone responsible for read and write traffic. Here's how this architecture looks like:
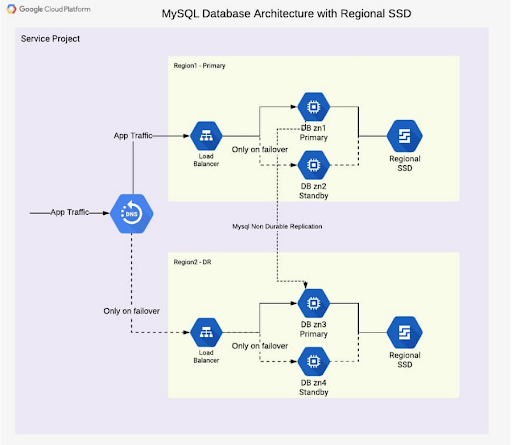
In addition to setting up the database servers, it is also necessary to implement a regional drive that is written to two zones simultaneously, to ensure safety in case of failure in any region. there. This is a huge advantage of Google Cloud, allowing you to bypass MySQL-level replication in a region. Each disk write operation is performed synchronously in two regions. When the primary server fails, a backup server is attached to the disk(s) in the region, and the database service (MySQL) is then similarly started. This gives the peace of mind of not worrying about replication latency or database state for high availability.
From a disaster recovery process perspective, the following things happen over time when something goes wrong:
- Normal steady state database operation
- An error occurs and a sector becomes inoperable or the database is inaccessible
- It must be decided whether the system is 'dead' (in the case where it is expected that the region will be back up soon or the server is back up).
- DNS is updated manually, so it redirects application traffic to the second zone
- Resume operation in the main area after the server is back to normal (optional), as the second zone has also been deployed, fully built
From a high-availability process standpoint, the following can happen over time in many situations:
- Normal steady state database operation
- Database server not working
- Start the backup server
- Mount regional SSD and enable database
- Automatically redirect application traffic to standby through load balancers
- After the server crashes or becomes unavailable again, is there a backup system?
A highly available database architecture will aid in disaster recovery. With sector disks and load balancers, it's simple to deploy flexible databases.
See more about load balancers and regional disks, HA and DR procedures, detailed steps in the beginning of this document. Try to familiarize yourself with the architecture as well as the failover process.
Source: Gimasys
Related Posts