Ngày 02/04 vừa qua, hội thảo trực tuyến do Gimasys phối hợp cùng Google Cloud…
Get your BigQuery production sample, all self-serving
A recap from part 1 about BigQuery autoreceive sample Google is proposing a solution for the problem of getting fresh PROD samples from BigQuery. The solution also provides safety measures to avoid accidental data exfiltration, and at the same time, it’s self-serving. You get a fresh sample every day. No more outdated schemas or stale samples.
How it works in detail
Wondering if this method will work for you, and if this solution is in line with your organization's security policy? Google's assumptions are that DevOps is not interested in preparing samples themselves and that it is better to let data scientists serve themselves. First of all because it is not the responsibility of DevOps to reason about data, whereas it is where data scientists are the subject matter experts.
DevOps
In this case, Google assumes you only want to evaluate once whether you have data access to a particular table in production. Google also assumes that you don't want to manually mediate each sample request. This means you can encode your review in a simple JSON file that Google calls a policy.
Policy
In the following JSON example, there are two parts, limit and default_sample:
- limit: Determines the maximum amount of data you can retrieve from a table. You can specify an amount, a percentage, or both. In case you specify both, the percentage will be converted to quantity and the minimum amount between the percentage (converted to quantity) and quantity will be used.
- default_sample: Used in case the request does not exist or has an “error” such as a non-JSON file or an empty file.
Eg:
{
“limit”: {
“count”: 300000,
“percentage”: 40.1
},
“default_sample”: {
“size”: {
“count”: 9,
“percentage”: 6.5
},
“spec”: {
“type”: “random”
}
}
}
Assumed use as a data scientist
Google assumes that you are a data scientist who wants to determine whether you have access to production data. Once you have access, you will request different samples whenever you need them. When you wake up the next day, your samples will be ready for you. Take a look at the following request formats:
A request has the same structure as an item default_sample in policy, including:
- size: Specify the amount of table data you want. You can specify an amount, a percentage, or both. In case you specify both, the larger value between quantity and percentage (converted to quantity) will be used as the actual value.
- spec: Specifies how to sample production data by providing the following information:
- type: Can be sorted or random.
- properties: If sorted, specify which column to use for sorting and the sorting direction:
- by: Column name.
- direction: Sorting direction (can be ASC or DESC).
Eg:
{
“__doc__”: “Full sample request”,
“__table_source__”: “bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2015”,
“size”: {
“count”: 3000,
“percentage”: 11.7
},
“spec”: {
“type”: “sorted”,
“properties”: {
“by”: “dropoff_datetime”,
“direction”: “DESC”
}
}
}
To be more specific about this content, Google will give an example. This will help you understand the limits and sizes when deploying on BigQuery.
The limit is not the size
There is a small but important difference in how limit differs from size. In the policy, you have a limit, using the smallest value between the amount and the percentage. Limits are used to limit the amount of data provided. Size used for default requests and sampling. It uses the largest value between the number and the percentage, the size cannot exceed the limit.
How limits and dimensions work in BigQuery
The table in this scenario has 50,000 rows.
| Field | Where | count | percentage |
| limit | Policy | 30,000 | 10 |
| size | Request | 10,000 | 40 |
It is then converted to:
| Field | Where | count | percentage | % in row count | Final value | Semantic |
| limit | Policy | 30,000 | 10 | 5,000 | 5,000 | min(30000, 5000) |
| size | Request | 10,000 | 40 | 20,000 | 20,000 | max(10000, 20000) |
In this case, the sample size is limited to 5,000 rows, or 10% of 50,000 rows.
Sampling cycle
In the Figure below, you have the flow of data sampling bypassing the infrastructure:
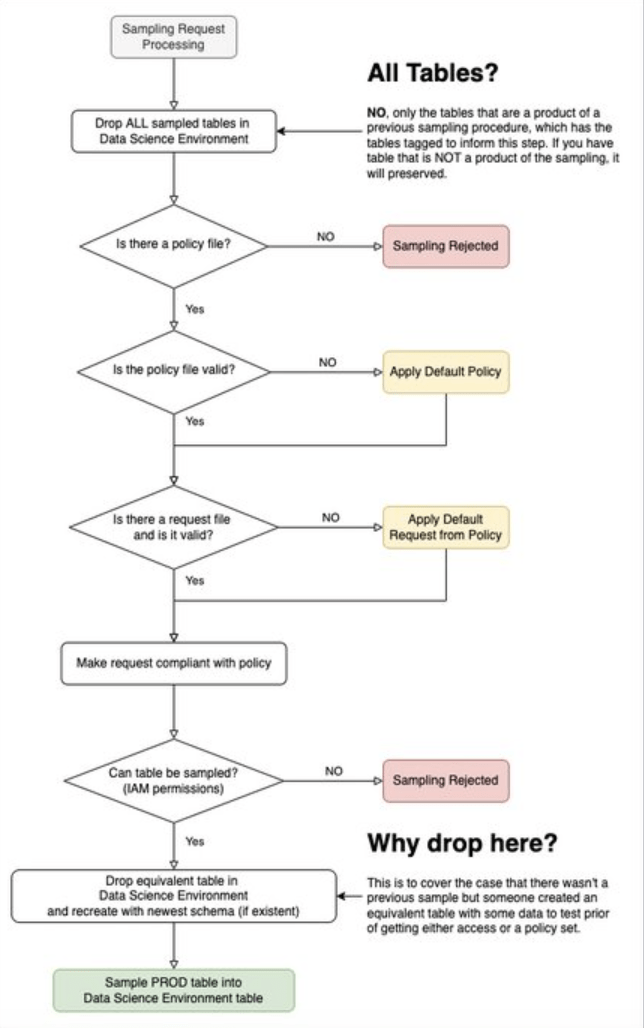
Hình trên có thể trông có vẻ phức tạp và người dùng cần đảm bảo rằng:
- Sample inflation should not occur, i.e. your sample should not increase with each sampling cycle. This means that policies must be followed.
- You are responsible for invalid requests.
- Keep schemas in sync with production.
In detail, the sampler has the following flow:
- Cloud Scheduler places a START message into PubSub's COMMAND topic. It tells the sampler function to start sampling.
- The sampler function will do the following:
- Delete all previous samples in the Data Science environment.
- Lists all available policies in the policy bucket.
- For each table it finds, sends a SAMPLE_START command with the corresponding policy.
- For each SAMPLE_START command, check to see if a corresponding request file exists. They are in the request bucket.
- Requests are checked according to policy.
- A compliance sampling request is sent to the BigQuery source. It is inserted into the corresponding table in the Data Science Environment.
- Every error the sampler function finds, it reports to PubSub's ERROR topic.
- The error handling function is triggered by any message in this topic. It sends email notification of errors.
- Assume that the sampler function is not executed within 24 hours. It then triggers an alert to be sent to PubSub's ERROR topic.
- If there is a “fatal” error in either the sampling or the error handling function, it sends an email alert.
Limitations
Google will cover each point in detail in the following sections. For reference, here's a short list of things Google doesn't support:
- JOINs of any kind
- WHERE clauses
- Auto-obfuscation (the data is auto-anonymized before inserting the sample)
- Column exclusion
- Row exclusion
- Correct uniform sampling distribution
- Non-uniform data sampling distributions (such as Gaussian, PoGoogler, and Pareto)
Google will provide “explanations” for “NOs” – most of which fall into one of the following categories:
- It is too complex and time consuming to implement.
- You can use views.
- It would be too expensive for you to have it.
JOINs and WHEREs
The problem with JOINs and WHEREs is that they are too complex to implement to enforce a sampling policy. Here is a simple example:
- Table TYPE_OF_AIRCRAFT, which is a simple ID for a specific aircraft, for example, Airbus A320 neo has ID ABC123. 100% of the data is sampled, that is you can copy the table.
- Table FLIGHT_LEG, which is a single flight on a specific day, for example, London Heathrow to Berlin at 14:50 Sunday. Ten percent is sampled.
- Table PASSENGER_FLIGHT_LEG provides which passenger is sitting where in a particular FLIGHT_LEG. Only 10 rows are allowed.
You can now construct a query that joins all of these tables together. You can ask all passengers flying in a particular aircraft type on a particular day. In this case, to honor the policies, Google have to do the following:
- Execute the query.
- Verify how much data from each particular table is being pulled through it.
- Start capping based on the "allowances".
This process will be:
- Hard to implement without a SQL AST.
- Probably very expensive for you. Therefore, Google will execute and then "trim" (you are paying for the full query).
- Can have many edge cases that violate the policies.
- Risk of data exfiltration.
Obfuscate data
Google hiểu rằng nhiều người dùng cần làm mờ dữ liệu vì tính chất bảo mật. Việc này được giải quyết bởi Cloud DLP và cũng có nhiều giải pháp có khả năng hơn trên thị trường mà bạn có thể sử dụng. Xem bài viết trên blog: Quản lý dữ liệu của bạn: sử dụng Cloud DLP để nhận diện và làm mờ thông tin nhạy cảm.
Column & row exclusion operations
Google agrees that excluding columns and rows is simple, and it's even easier and safer to use views or Cloud DLP. The reason Google didn't do this here is because it's a difficult use case to create a generic specification that would work for all use cases. Additionally, there are much better approaches like Cloud DLP. It all depends on why you want to remove the column or row.
Does uniformity occur during implementation?
Except for views, Google relies on TABLESAMPLE statements for cost reasons. A truly random sample means using the ORDER BY RAND() strategy, which requires a full table scan. With TABLESAMPLE statements, you only pay a little more for the amount of data you want.
Note about TABLESAMPLE statements
This technique allows Google to sample a table without reading the entire thing. But there is a big NOTE when using TABLESAMPLE. It is neither truly random nor uniform. Your sample will have bias in your table blocks. Here's how it works, according to this document
The following example reads approximately 20% of the data blocks from storage and then randomly selects 10% of the rows in those blocks:
SELECT * FROM dataset.my_table TABLESAMPLE SYSTEM (20 PERCENT)
WHERE rand() < 0.1
An example is always easier. Let us build one with a lot of skewness to show what TABLESAMPLE does. Imagine that your table has a single integer column. Now picture that your blocks have the following characteristics:
| Block ID | Average | Distribution | Description |
| 1 | 10 | Single value | All values are 10 |
| 2 | 9 | Single value | All values are 9 |
| 3 | 5 | Uniform from 0 to 10 | |
| 4 | 4 | Uniform from -1 to 9 | |
| 5 | 0 | Uniform from -5 to 5 |
At this point, we are interested in looking at what happens to the average of your sample when using TABLESAMPLE. For simplicity, assume:
- Each block has 1,000 records. This puts the actual average of all values in the table to around 5.6.
- You chose a 40% sample.
- TABLESAMPLE will sample 40% of the blocks and you will get two blocks. Let us look at your average. Let us assume that blocks with Block ID 1 and 2 Googlere selected. This means that your sample average is now 9.5. Even if you use the downsampling that is suggested in the documentation, you will still end up with a biased sample. Simply put, if your blocks have bias, your sample has it too.
Again, removing the potential bias means increasing the sampling costs to a full table scan.
In case users need more than other distribution boards
There are several reasons why not. The main reason is that other distributions aren't supported by the SQL engine. There is no workaround for the missing feature. The only way to have it is to implement it. Here is where things get complicated. Fair warning, if your stats are rusty, it is going to be rough.
All the statements below are based on the following Googleird property of the cumulative distribution function (CDF):
For it to work, you will need to do the following:
- Get all data on the target column (which is being the target of the distribution).
- Compute the column's CDF.
- Randomly/uniformly sample the CDF.
- Translate the above to a row number/ID.
- Put the rows in the sample.
This process can be done, but has some implications, such as the following:
- You will need a full table scan.
- You will have to have a "beefier" instance to hold all of the data (think billions of rows), and you will have to compute the CDF.
This means that you will be paying for the following:
- The already expensive query (full table scan).
- Time on the expensive instance to compute the sample.
Views: the workaround
Google hỗ trợ lấy mẫu từ các views. Điều này có nghĩa là bạn luôn có thể đóng gói điều này và để trình lấy mẫu thực hiện công việc của nó. Nhưng các views không hỗ trợ câu lệnh TABLESAMPLE của BigQuery. Điều này có nghĩa là các mẫu ngẫu nhiên cần quét toàn bộ bảng bằng chiến lược ORDER BY RAND(). Quét toàn bộ bảng không xảy ra trên các mẫu không ngẫu nhiên.
Liệu việc này có gian lận hay không?
It is precisely this practice that Google admits to “cheating” with the alternative of using views pushing responsibility onto SecOps and DataOps, who will need to define compliant views and sampling policies. Also, it can be expensive, since querying the view is like executing the basic query and sampling it. Be especially careful with random samples from views due to their full table scan nature on views.
Solution design
Google settled around a very simple solution that has the following components:
- BigQuery: The source and destination of data.
- Cloud Scheduler: Our crontab to trigger the sampling on a daily or regular basis.
- Cloud Pub/Sub: Coordinates the triggering, errors, and sampling steps.
- Cloud Storage: Stores the policies and requests (two different buckets).
- Cloud Functions: Our workhorse for logic.
- Secret Manager: Keeps sensitive information.
- Cloud Monitoring: Monitors the health of the system.
Source: Gimasys
Related Posts