Tư duy ưu tiên bảo mật của Google xuất phát từ hơn hai thập kỷ…
What is Datastream? Information to know about Datastream
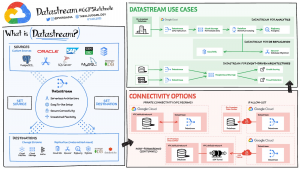
What is Datastream?
With the volume of data constantly increasing, many companies find it difficult to use data effectively and derive insights from it. Often these organizations are burdened with cumbersome and difficult-to-maintain data architectures.
One way companies are addressing this challenge is change streaming: the movement of changing data as they happen from source (usually a database) to destination. Powered by change data capture – CDC (change data capture), change streaming has become an important data architecture building block. We recently announced Datastream, a serverless data collection change and copy service. Key capabilities of Datastream include:
- Duplicate and synchronize data across your organization with minimal latency. You can reliably synchronize data across heterogeneous databases and applications, with low latency and minimal impact on your power performance. Harness the power of data flows for analytics, database replication, cloud migration, and event-driven architectures across hybrid environments.
- Scale up or down with a serverless architecture seamlessly. Get up and running quickly with an easy-to-use and serverless service that scales seamlessly as your data volumes change. Focus on gleaning up-to-date insights from your data and responding to high-priority issues, instead of infrastructure management, performance tuning, or resource provisioning.
- Integration with data integrators Google Cloud Platform. Kết nối dữ liệu trong tổ chức của bạn với các sản phẩm tích hợp dữ liệu Đám mây của Google. Datastream tận dụng các mẫu Dataflow để tải dữ liệu vào BigQuery, Cloud Spanner và Cloud SQL; nó cũng hỗ trợ các đầu nối CDC Replicator của Cloud Data Fusion để tổng hợp dữ liệu dễ dàng hơn bao giờ hết.
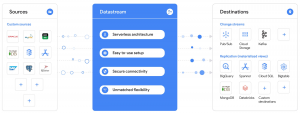
Use cases
Datastream captures change streams from Oracle, MySQL, and other sources for destinations such as Cloud Storage, Pub/Sub, BigQuery, Spanner, etc. Some use cases of Datastream:
- For analytics use Datastream with pre-built template . to create up-to-date replication tables in BigQuery in a fully managed manner.
- For database replication, use Datastream with pre-built Dataflow templates to continuously copy and synchronize database data into Cloud SQL for PostgreSQL or Spanner to support low downtime database migrations or hybrid cloud configurations.
- To build an event-driven architecture, use Datastream to ingest changes from multiple sources into object stores like Google Cloud Storage or in the future, messaging services like Pub / Sub or Kafka
- Streamline real-time data pipelines that seamlessly transfer data from legacy relational data warehouses (like Oracle and MySQL) using Datastream into MongoDB.
How do you set up the Datastream?
- Create a power connection profile.
- Create a destination connection profile.
- Create a stream using source and destination connection profiles, and define objects to get from the source.
- Authenticate and start the stream.
Once started, a stream continuously transmits data from source to destination. You can pause and then resume the live stream.
Connection options
To use Datastream to create a stream from the source database to the destination, you must establish a connection to the source database. Datastream supports IP whitelist, SSH tunnel forwarding, and VPC peer-to-peer networking methods.
Private connection configuration allows Datastream to communicate with the data source over a private network (internally within Google Cloud or with external sources connected via VPN or Interconnect). This communication occurs through a Virtual Private Cloud (VPC) peer-to-peer connection.
Source: Gimasys
Related Posts