
Sự kiện Google I/O 2025 vừa qua đã thực sự làm "khuynh đảo" giới công…
Google Cloud provides easy access to flow analytics with SQL, real-time AI and more
During challenging and uncertain times, businesses around the world must think creatively and create more value with fewer resources to maintain reliable and efficient systems for their business. customers have needs. In terms of data analytics, it's important to find ways for startup engineering teams and operations teams to work on unique scenarios to maintain the required level of productivity. Balancing the development of modern, high-value threading pipelines with cost-effective batch workflow maintenance and optimization is an important goal for many teams. Google has implemented new capabilities to make it easy for developers and operations teams to access flow analytics.
Highlights of these launches include:
- Flow pipelines are developed directly in the BigQuery web UI with general availability of Dataflow SQL
- Dataflow integration with AI Platform enables simple development of advanced analytics use cases
- Enhanced monitoring with dashboard with visibility
Built on the automation infrastructure of Pub/Sub, Dataflow and BigQuery, Google Cloud's stream processing platform provides the resources that engineering and operations teams need to ingest, process, and analyze fluctuating volumes of data in real time to gain insights real-time business. We are very honored when Forrester Wave™: Streaming Analytics, the Q3 2019 report named Google Cloud as the leader in the space. These launches build on and reinforce the capabilities that drive that recognition.
What's New in Stream Analytics?
Development for batch data and stream pipelines is made even easier with major releases on both Dataflow and Pub/Sub. You can get from idea to path and manage iteratively to meet customer needs efficiently.
The launch of Dataflow SQL
Dataflow SQL cho phép các nhà phân tích dữ liệu và kỹ sư dữ liệu sử dụng các kỹ năng SQL của họ để phát triển các đường dẫn truyền dữ liệu Dataflow ngay trên giao diện người dùng web BigQuery. Các đường dẫn SQL Dataflow của bạn có quyền truy cập đầy đủ vào tự động hóa, cửa sổ dựa trên thời gian, công cụ xử lý trực tuyến và xử lý dữ liệu song song. Bạn có thể tham gia truyền dữ liệu từ Pub / Sub với các tệp trong Cloud Storage hoặc các bảng trong BigQuery, viết kết quả vào BigQuery hoặc Pub / Sub và xây dựng bảng điều khiển thời gian thực bằng Google Sheets hoặc các công cụ BI khác. Ngoài ra, còn có một giao diện dòng lệnh được thêm vào gần đây để viết lệnh các công việc sản xuất của bạn với sự hỗ trợ đầy đủ của các tham số truy vấn và bạn có thể dựa vào tích hợp danh mục dữ liệu và trình soạn thảo lược đồ tích hợp để quản lý lược đồ.
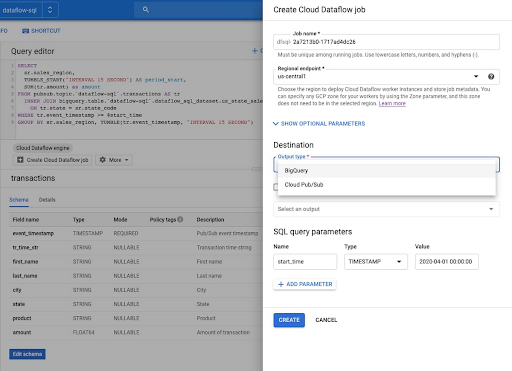
Iterative pipeline development in Jupyter notebook
With notebooks, developers can now iteratively build pipelines from scratch with the Notebook AI platform and deploy with the Dataflow runner. Authoring Apache Beam pipelines step-by-step by examining the path graphs in the read-experience-in-iteration (REPL) workflow. Available through Google's AI Platform, Notebook lets you write pipelines in a visual environment with the latest machine learning and data science frameworks so you can develop better customer experiences with ease.
Share paths and scales with flex templates
Dataflow templates let you easily share your links with team members and across your organization, or take advantage of the many templates provided by Google to perform simple but useful data processing tasks. With flex templates, you can create a template from any Dataflow pipeline.
Launching Pub / Sub deal letter topics
Operating reliable flow paths and event-driven systems has become simpler with the general availability of dead letter topics for Pub/Sub. A common problem in these systems are “dead letters,” or messages that cannot be processed by the subscriber application. A dead letter topic allows such messages to be set aside for offline testing and debugging so that the rest of the message can be handled without delay.
Streamline data processing optimization with variable data collection (CDC)
One way to optimize processing of stream data is to focus on working with only the changed data instead of all available data. This is where change data collection (CDC) comes in handy. The Dataflow team has developed a sample solution that allows you to import a stream of change data coming from any type of MySQL database on versions 5.6 and later (self-managed, on-premises, etc.) Model it with datasets in BigQuery using Dataflow.
Integration with Cloud Platform AI
Now you can take advantage of easy integration with AI Platform APIs and access to libraries for implementing advanced analytics use cases. AI Platform and Dataflow capabilities include video clip classification, image classification, natural text analysis, data loss prevention, and several other streaming predictive use cases.
Ease and speed shouldn't come to those building and starting data pipelines, but neither should those managing and maintaining them. Google has also enhanced the monitoring experience for Dataflow, which aims to empower operational teams even more.
Reduce operational complexity with an observation panel
Observation panel and Dataflow inline monitoring gives you direct access to job metrics to help troubleshoot batch and flow pipelines. You can access monitoring graphs at both step- and worker-level visibility, and set alerts for conditions like stale data and high system latency. Below, look at an example:
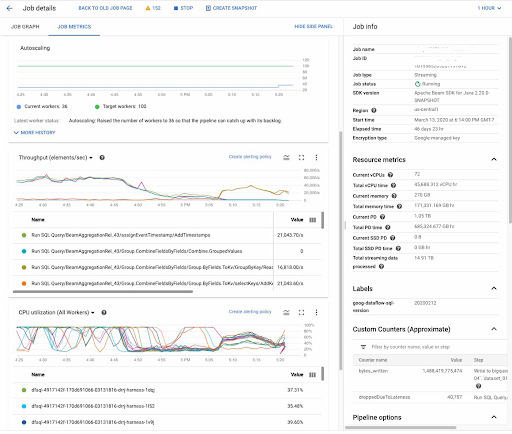
Getting started with stream analytics is now easier than ever. The first step to getting started with testing and experimentation is to move some data onto the platform. Check out the Pub/Sub Quick Start docs to get moving with real-time texting and typing with Cloud GCP.
Source: Gimasys
Related Posts


