Ngày 02/04 vừa qua, hội thảo trực tuyến do Gimasys phối hợp cùng Google Cloud…
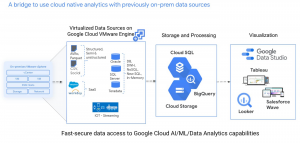
Optimizing BigQuery with data sources in Google Cloud VMware Engine

For customers who have migrated data sources from the on-premise system to Google Cloud VMware Engine (https://cloud.google.com/vmware-engine) and want to use data and analytics services provided by Google Cloud. One of the goals of customers who choose Google Cloud is to leverage Google Cloud analytics with their data sets. If you are an IT decision maker or data architect who wants to quickly leverage the power of your data with Google analytics, this blog describes methods for accessing your data in BigQuery, nơi có thể thực hiện phân tích nâng cao và machine learning trên bộ dữ liệu của bạn.
> Reference:
- Introducing Datastream for Google BigQuery
- Analyze Big Data with BigQuery and Google Sheets
- How to migrate data warehouse on premises to BigQuery on Google Cloud
Why?
Data consumption and analytics are at the forefront of technology. Customers today use and manage large amounts of data and resources. These challenges create an opportunity for Google Cloud to help manage and understand your existing databases without the need for costly re-architecture of your source documents or data locations. This blog covers approaches to accessing Google Cloud data and analytics services using your existing data without having to re-architect your database. Once your data sources are in Google Cloud VMware Engine, Google's highly available and fault-tolerant infrastructure can be leveraged to enhance the performance of your data pipelines. These solutions aim to reduce the time it takes to extract value from your data sets with cloud-native analytics available through BigQuery.
This Google Cloud VMware Engine migration solution brings advantages to all parts of data operations. Database administrators (DBAs) and virtual infrastructure/cloud administrators can use familiar environments similar to on-premises in the cloud. On-premises infrastructure teams can enable data scientist / AI / machine learning (ML) teams to use familiar toolsets. These teams now have access to Google Cloud AI/ML/data analytics capabilities for their on-premises data.
For example, if you want to explore cross-selling opportunities in your products, the first step is to ensure that the payment and product usage data sets across your products are connected for analysis . The DBA team will identify these data sets and the infrastructure team will enable access to these sources. The application team then copies this data to BigQuery and uses approaches such as BigQuery ML Recommendations (https://cloud.google.com/bigquery-ml/docs/bigqueryml-mf-explicit-tutorial) to explore cross-selling opportunities. Another example use case is forecasting usage growth for operations and growth planning. Once your sales data is replicated in BigQuery, advanced methods time series forecasting will be available to your dataset.
What does this include?
Methods for replicating your relational datasets in BigQuery in a private and secure way using Google Cloud Data Fusion (https://cloud.google.com/data-fusion/) or Google Cloud Datastream (https://cloud.google.com/datastream). Datafusion is an ETL tool that supports many different types of data pipelines. Datastream is a service for collecting and replicating change data. Using both of these services, data stays within your projects in Google Cloud, and internal IPs are used to access the data. We'll focus on real-time replication so you can continuously access your data from operational data stores, such as SQL Server, MySQL, and Oracle in BigQuery.
Moving data from your data sources to the cloud and maintaining the data pipeline to your data warehouse through Extract – Transform – Load (ETL) is an activity. time-consuming. An alternative approach is ELT (Extract Load Transform). ELT methods load data into the target system (e.g. BigQuery) before transforming the data. The ELT process is often preferred over the traditional ETL process because it is simpler to realize and loads data faster.
With your data sets now in Google Cloud, data teams can use Cloud Data Fusion and Datastream over the high-speed, low-latency Google Cloud network to replicate or move data from the infrastructure Your VMware to different destinations in Google Cloud Platform, such as Google Cloud native Storage buckets or BigQuery.
For simplicity, it will be assumed that all services are used in the same project. And we'll also discuss some pricing implications when moving data from Google Cloud VMware Engine from on-premises or another virtual private cloud (VPC).

Cloud Data Fusion:
Cloud Data Fusion provides an intuitive point-and-click interface that enables ETL/ELT data pipeline deployment without code. Cloud Data Fusion also provides a replication accelerator that allows you to replicate your tables into BigQuery.
Cloud Data Fusion internally sets up a tenant project with its own VPCs to manage Cloud Data Fusion resources. To access data sources in Google Cloud VMware Engine using Cloud Data Fusion, we use a reverse proxy on the primary VPC. This is depicted in the image below.
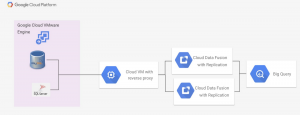
In this case, Google has its data workloads running on the Google Cloud VMware Engine instance in the project. The Google Cloud VMware Engine environment is accessed through a project-level VPC peering with the Google Cloud VMware Engine. Version Google Compute Engine at the VPC project level exposes a reverse proxy to the Google Cloud VMware Engine database for services that cannot directly access the Google Cloud VMware Engine instance. Cloud Data Fusion instances are enabled with private IP access and peering to the primary VPC, and data can be accessed through a reverse proxy instance. The procedure for setting up internal IP and peer-to-peer access on Cloud Data Fusion is described in document This.
Once this peering process is complete, use the Java Database Connectivity connector in Cloud Data Fusion to access our database for replication or for advanced ETL operations. To enable change data capture, we need to enable the database in Google Cloud VMware Engine to track and capture changes to the database. This entire setup and scaling process is described in the documentation for MySQL (https://cloud.google.com/data-fusion/docs/tutorials/replicating-data/mysql-to-bigquery) and SQL Server.
Google Cloud Datastream:
Datastream is a serverless change capture and replication service. You can access streaming, low-latency data from Oracle and MySQL databases on Google Cloud VMware Engine. This approach provides more flexibility in managing data flow pipelines. This solution is currently in general availability and is only available in certain regions.
This option also requires a reverse proxy to be configured in the Google Compute Engine instance. This reverse proxy is used to access data sources in Google Cloud VMware Engine. This option is described in document This
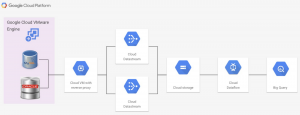
You can find the complete setup to use Datastream in instructions on how to do this. To enable replication, we need a stream configured on Datastream, which accesses data from the database and transfers it to the cloud storage. The reverse proxy data access flow needs to be exposed on the customer's VPC. To pass data to BigQuery, use pre-configured Datastream sample to BigQuery in ..
How to get started?
The first step is migrate workloads to Google Cloud VMware Engine. Your cloud administrator/architect will typically drive this. If not already identified during the migration phase, the next step is to identify the databases residing on virtual machines hosted in Google Cloud VMware Engine and recreate the existing reports using BigQuery. In most organizations there will be many individuals involved in this process. For example, a data architect may be the best source for information about data sources, a solutions architect will have insights into cost/performance and other Infrastructure inputs will be needed for network interfaces. The steps below outline one possible approach to enable this movement.
- Identify data sets residing on virtual machines migrated to Google Cloud VMware Engine used for reports.
- Choose the right pipeline (Datastream vs Data Fusion) based on database type and pipeline requirements (price/performance trade-off and ease of use).
- Based on the data pipeline, select the appropriate region. There are no data export fees within the same region.
- Set up a reverse proxy for the Google Cloud VMware Engine dataset.
- Set up replication service with performance parameters based on required replication performance.
- Enable analytics and visualization based on business requirements across the data set.
Conclude:
Google Cloud VMware Engine service is a quick and easy way to enable data visualization and analytics using your existing data sets. Now you can leverage your existing infrastructure operations posture on VMware to enable cloud analytics without spending time refactoring your database. These approaches enable you to take advantage of the performance benefits of dedicated hardware on Google Cloud, connected to the most advanced data capabilities in the world.
Source: gcloudvn.com
Related Posts